Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
|| Name | Age | City | |----|----------|-----|------------| |0| Alice |25| Niu York |-- 行索引(0, 1, 2, 3)标识每一行的位置 |1| Bob |30| Los Angeles|-- 列索引(Name, Age, City)表示不同的数据字段 |2| Carol |28| Chicago |-- 每一列(Name, Age, City)都包含相应的数据 |3| David |22| Houston |-- 每一列都是一个 Pandas Series,包含相同类型的数据
<!-- 定义查询 --> <selectid="selectUser"resultType="User"> SELECT * FROM users WHERE id = #{id} </select> <!-- 映射结果到对象 --> <resultMapid="BaseResultMap"type="User"> <idcolumn="id"property="id"/> <resultcolumn="username"property="username"/> <resultcolumn="password"property="password"/> </resultMap>
1.2 注解方式
1 2
@Select("SELECT * FROM users WHERE id = #{id}") User selectUser(int id);
核心功能:
动态 SQL:MyBatis 允许你在 XML 中编写动态 SQL 语句,可以根据条件动态构建 SQL 查询。
1 2 3 4 5 6 7 8 9 10
<selectid="selectUsers"parameterType="map"resultType="User"> SELECT * FROM users WHERE 1=1 <iftest="username != null"> AND username = #{username} </if> <iftest="password != null"> AND password = #{password} </if> </select>
参数传递:MyBatis 支持多种参数传递方式,包括单个参数、多个参数、Map 和注解等。
1 2
@Select("SELECT * FROM users WHERE id = #{id} AND username = #{username}") User selectUserByIdAndUsername(@Param("id")int id, @Param("username") String username);
批处理:MyBatis 允许执行批处理操作,可以有效地执行一组 SQL 语句。
1 2 3 4 5 6 7 8
SqlSessionsqlSession= sqlSessionFactory.openSession(ExecutorType.BATCH); UserMapperuserMapper= sqlSession.getMapper(UserMapper.class); for (User user : userList) { userMapper.insertUser(user); } sqlSession.flushStatements(); sqlSession.commit(); sqlSession.close();
DO(Data Object):通常表示数据库中的数据实体,对应数据库表的结构。它主要用于数据存储和数据库操作,包含与数据库表字段一一对应的属性。类中通常包含与数据库表字段对应的成员变量、getter 和 setter 方法。它不应包含业务逻辑,主要负责数据的持久化和映射。 尽管 PO 和 DO 在一些情况下用法相似,但它们的侧重点有所不同。PO 更侧重于与数据库的交互,强调持久化和数据表映射;而 DO 侧重于在不同层之间传递数据,强调业务逻辑层面的数据封装。
BO(Business Object):通常表示业务层的业务实体,主要用于封装业务逻辑。BO 类一般包含与业务逻辑相关的属性和方法,与具体的数据存储形式无关。包含了一些业务逻辑的操作,比如计算、验证等。它不应直接与数据库进行交互,而是通过调用 Service 层或 DAO 层的方法实现数据的获取和存储。
SELECTdistinct id FROM users; LIMIT 2, 3; ORDERBY col1 DESC, col2 ASC; WHERE col isNULL; -- 子查询:只能返回一个字段的数据,可以将子查询的结果作为 WHRER 语句的过滤条件,配合 (not )in SELECT*FROM mytable1 WHERE col1 IN (SELECT col2 FROM mytable2); -- 分组:将数据按照一个或多个列的值分成不同的组,常与聚合函数(如 SUM、COUNT、AVG 等)一起以对每个组聚合操作 -- GROUP BY 子句: 用于指定按哪些列进行分组; HAVING 子句: 用于对分组后的数据进行筛选。 -- WHERE 过滤行,HAVING 过滤分组,行过滤应当先于分组过滤。 SELECT col, COUNT(*) AS num FROM mytable WHERE col >2 GROUPBY col HAVING num >=2 ORDERBYSUM(column2) DESC;
SELECT:查询出属性,用 AS 给列名、计算字段和表名取别名,以简化 SQL 语句以及连接相同表; select 中 sql 函数计算出的值作为查询出的属性(select round(count()/3, 2) from ..) select 中可以加一个select 用于属性计算(select id, count()/(select count(*) from Users) per from ..) 若有重复列,使用 DISTINCT 去除重复值
LIMIT:LIMIT 2, 3 返回第 3 ~ 5 行。配合排序实现获取最大/最小值。。
WHERE:过滤行,AND 和 OR 用于连接多个过滤条件。优先处理 AND,使用 () 决定优先级; is 搭配 null,IN 操作符用于匹配一组值,其后也可以接一个 SELECT 子句,从而匹配子查询得到的一组值。
ORDER:可以按多个列进行排序,并指定不同的排序方式,默认升序ASC, 降序DESC
GROUP BY 可以放在 WHERE 前、后,想清楚在分组前、后过滤
子查询的结果需要指定别名。
连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
-- 连接(内连接):返回多个表中匹配条件满足的行,不匹配的行不会被包括在结果集中。 -- 使用 (INNER )JOIN 关键字,条件语句使用 ON 而不是 WHERE,连接可以替换子查询且效率一般会更快。 SELECT A.value, B.value FROM tablea AS A JOIN tableb AS B ON A.key = B.key; -- 自连接:可以看成内连接的一种,只是连接的表是自身而已。 SELECT e1.name FROM employee AS e1 INNERJOIN employee AS e2 ON e1.department = e2.department AND e2.name = "Jim"; -- 自然连接:自然连接是把同名列通过等值测试连接起来的,同名列可以有多个。 -- 内连接和自然连接的区别: 内连接提供连接的列,而自然连接自动连接所有同名列。 SELECT A.value, B.value FROM tablea AS A NATURALJOIN tableb AS B; -- 外连接:保留了没有关联的那些行。分为左,右外连接以及全外连接。 -- 左连接返回左表的所有行以及与右表匹配的行。如果右表中没有匹配的行,将会返回 NULL 值。 -- on 后等于新连接出了一张表,where 在新表上进行查询 select Employee.name, Bonus.bonus from Employee leftjoin Bonus on Employee.empId = Bonus.empId where Bonus.bonus <1000or Bonus.bonus isnull
SQL 函数
数学函数:SUM():计算指定列的总和。 AVG():计算指定列的平均值。 MAX():找出指定列的最大值。 MIN():找出指定列的最小值。 COUNT():计算指定列的行数。 ROUND(x,y):把 x 四舍五入到 y 位小数。 ABS():返回绝对值。
B+Tree 索引:是大多数 MySQL 存储引擎的默认索引类型。因为不再需要进行全表扫描,只需要对树进行搜索即可,因此查找速度快很多。除了用于查找,还可以用于排序和分组。 InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
全文索引:MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。查找条件使用 MATCH AGAINST,而不是普通的 WHERE。全文索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
索引的优点:大大减少了服务器需要扫描的数据行数。帮助服务器避免进行排序和分组,也就不需要创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,因为不需要排序和分组,也就不需要创建临时表)。将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,也就将相邻的数据都存储在一起)。
是大多数 MySQL 存储引擎的默认索引类型因为不再需要进行全表扫描,只需要对树进行搜索即可,因此查找速度快很多。除了用于查找,还可以用于排序和分组可以指定多个列作为索引列,多个索引列共同组成键. 适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。 InnoDB 的 B+Tree 索引分为主索引和辅助索引. 主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
索引优化
1.独立的列 在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。例如下面的查询不能使用 actor id 列的索引: 2.多列索引 在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor id和 film id 设置为多列索引。 3.索引列的顺序 4.前缀索引对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。对于前缀长度的选取需要根据索引选择性来确定。 5.覆盖索引
在系统和 MySQL 进行交互之前,MySQL 驱动会帮我们建立好连接,然后我们只需要发送 SQL 语句就可以执行 CRUD 了。 java 系统在通过 MySQL 驱动和 MySQL 数据库连接的时候是基于 TCP/IP 协议的,多线程请求的时候频繁的创建和销毁连接显然是不合理的。在访问 MySQL 数据库的时候,建立的连接并不是每次请求都会去创建的,而是从数据库连接池中去获取,这样就解决了因为反复的创建和销毁连接而带来的性能损耗问题了。MySQL 的架构体系中也已经提供了这样的一个池子,也是数据库连池。双方都是通过数据库连接池来管理各个连接的,这样一方面线程之前不需要是争抢连接,更重要的是不需要反复的创建的销毁连接。
网络连接必须由线程来处理
网络中的连接都是由线程来处理的,所谓网络连接说白了就是一次请求,每次请求都会有相应的线程去处理的。也就是说对于 SQL 语句的请求在 MySQL 中是由一个个的线程去处理的。 SQL 接口:MySQL 中处理请求的线程在获取到请求以后获取 SQL 语句去交给 SQL 接口去处理。 查询解析器:会将 SQL 接口传递过来的 SQL 语句进行解析,翻译成 MySQL 自己能认识的语言 MySQL 查询优化器:查询优化器内部具体怎么实现的我们不需要是关心,我需要知道的是 MySQL 会帮我去使用他自己认为的最好的方式去优化这条 SQL 语句,并生成一条条的执行计划,比如你创建了多个索引,MySQL 会依据成本最小原则来选择使用对应的索引,这里的成本主要包括两个方面, IO 成本和 CPU 成本。MySQL 优化器 会计算 「IO 成本 + CPU」 成本最小的那个索引来执行 存储引擎:查询优化器会调用存储引擎的接口,去执行 SQL,也就是说真正执行 SQL 的动作是在存储引擎中完成的。数据是被存放在内存或者是磁盘中的(存储引擎是一个非常重要的组件,后面会详细介绍) 执行器:执行器是一个非常重要的组件,因为前面那些组件的操作最终必须通过执行器去调用存储引擎接口才能被执行。执行器最终最根据一系列的执行计划去调用存储引擎的接口去完成 SQL 的执行
存储引擎
当我们系统发出这样的查询去交给 MySQL 的时候,MySQL 会按照我们上面介绍的一系列的流程最终通过执行器调用存储引擎去执行,流程图就是上面那个。 在执行这个 SQL 的时候 SQL 语句对应的数据要么是在内存中,要么是在磁盘中,如果直接在磁盘中操作,那这样的随机IO读写的速度肯定让人无法接受的,所以每次在执行 SQL 的时候都会将其数据加载到内存中,这块内存就是 InnoDB 中一个非常重要的组件:缓冲池 Buffer Pool
关于Buffer Pool、Redo Log Buffer 和undo log、redo log、bin log 概念以及关系: Buffer Pool 是 MySQL 的一个非常重要的组件,因为针对数据库的增删改操作都是在 Buffer Pool 中完成的 Undo log 记录的是数据操作前的样子 redo log 记录的是数据被操作后的样子(redo log 是 Innodb 存储引擎特有) bin log 记录的是整个操作记录(这个对于主从复制具有非常重要的意义) 、、,, ,。
从准备更新一条数据到事务的提交的流程描述
首先执行器根据 MySQL 的执行计划来查询数据,先是从缓存池中查询数据,如果没有就会去数据库中查询,如果查询到了就将其放到缓存池中
Linux 是一种免费、开源的类Unix操作系统内核。它最初由芬兰的Linus Torvalds在1991年创建,并迅速发展成为一个庞大且活跃的开源社区项目。Linux内核是操作系统的核心部分,但通常与 GNU 工具和其他软件一起使用,形成完整的(GNU/Linux)操作系统,通常被称为 Linux发行版(如 Ubuntu、Red Hat、CentOS)
GNU
GNU 计划,译为革奴计划,它的目标是创建一套完全自由的操作系统,称为 GNU,其内容软件完全以 GPL 方式发布。其中 GPL 全称为 GNU 通用公共许可协议,包含了以下内容: 1、以任何目的运行此程序的自由;2、再复制的自由;3、改进此程序,并公开发布改进的自由。
而在 Windows 系统上,PowerShell 是一个更现代、功能更强大的命令行工具,特别适用于系统管理和自动化任务。尽管命令行程序cmd 仍然存在并且仍然可以使用,但PowerShell已成为Windows系统管理和开发的首选工具。
WSL
WSL(Windows Subsystem for Linux)允许用户直接在 Windows 上运行Linux 环境(包括大多数命令行工具、实用程序和应用程序),无需修改,无需单独的虚拟机或双重启动。与完整虚拟机相比,WSL 需要的资源(CPU、内存和存储)更少。 WSL是 Windows10/11 自带的一个功能,默认是关闭的,旨在为希望同时使用 Windows 和 Linux 的用户提供无缝且高效的体验。能够在 Bash shell 中运行Linux,并选择您的发行版(Ubuntu、Debian、OpenSUSE、Kali、Alpine 等)。
开启 Hype-V:ctrl+r - control - 程序 - 开启Windows功能 - 勾选Hype-V
更新wsl版本;或手动下载最新版本的 Linux 内核更新包,运行(双击运行 - 系统将提示您提供提升的权限,选择“是”以安装)
1
wsl --update
将 WSL 2 设置为默认版本
1
wsl --set-default-version 2
安装Linux发行版,创建账号用户密码,Installation successful
1
wsl --install -d Ubuntu
至此,已成功安装并设置了一个与 Windows 操作系统完全集成的 Linux 发行版!下次,您可以以管理员身份打开 PowerShell 或 cmd 命令控制台,输入 wsl 命令即可打开安装好的Linux发行版(如Ubuntu)了。 注意:在wsl中,本地磁盘都位于 /mnt 目录。比如 c 盘位于 /mnt/c 。要进入 d 盘,执行命令 cd /mnt/d
DNS 缓存投毒 (DNS Spoofing): 攻击者通过篡改 DNS 查询结果,将用户导向恶意网站。
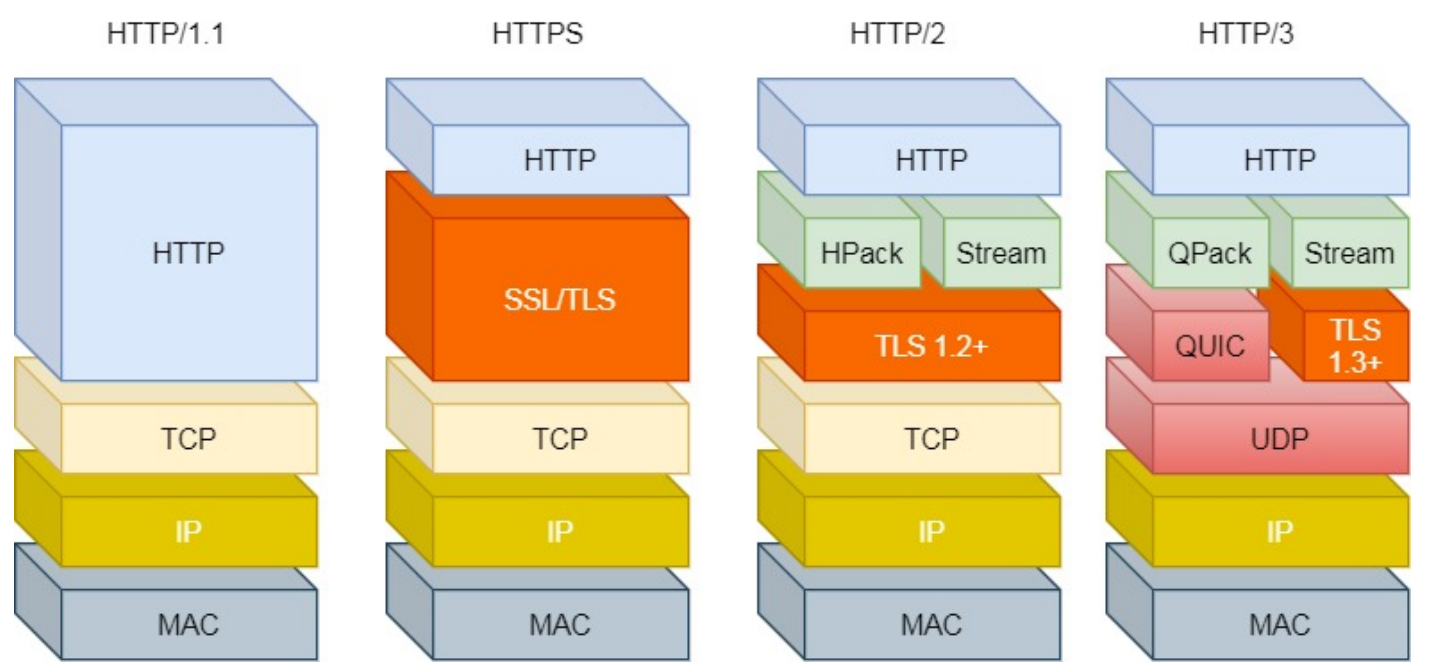
HTTP
2.1 HTTP 常见面试题
2.1.1 HTTP 基本概念
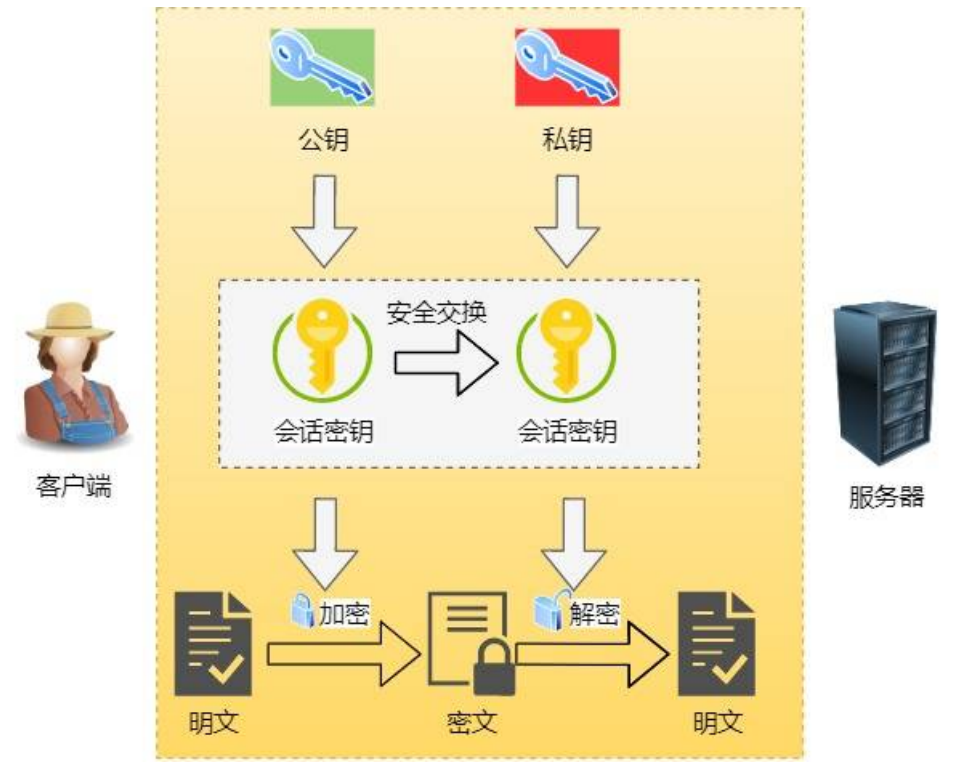
HTTP 是? 超⽂本传输协议,也就是HyperText Transfer Protocol。超⽂本,它就是超越了普通⽂本的⽂本,它是⽂字、图⽚、视频等的混合体,最关键有超链接,能从⼀个超⽂本跳转到另外⼀个超⽂本。HTML 是最常⻅的超⽂本,本身只是纯⽂字⽂件,但内部⽤很多标签定义了图⽚、视频等的链接,再经过浏览器的解释呈现出⼀个⽂字、有画⾯的⽹⻚。 HTTP 是⼀个在计算机世界⾥专⻔在「两点」之间「传输」⽂字、图⽚、⾳频、视频等「超⽂本」数据的「约定和规范」。
1 2 3 4 5 6 7 8
# 请求报文: 由请求行、请求头、空行和请求体组成。 GET /index.html HTTP/1.1 Host: www.example.com Connection: keep-alive # 响应报文: 由状态行、响应头、空行和响应体组成。 HTTP/1.1 200 OK Content-Type: text/html Content-Length: 123
常见状态码
1xx:1xx 类状态码属于提示信息,是协议处理中的⼀种中间状态,实际⽤到的⽐较少。
2xx:2xx 类状态码表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。 「200 OK」是最常⻅的成功状态码,表示⼀切正常。如果是⾮ HEAD 请求,服务器返回的响应头都会有 body 数据。 「204 No Content」也是常⻅的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。 「206 Partial Content」是应⽤于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部⽽是其⼀部分,也是服务器处理成功的状态。
4xx:表示客户端发送的报⽂有误,服务器⽆法处理,也就是错误码的含义。 「400 Bad Request」表示客户端请求的报⽂有错误,但只是个笼统的错误。 「403 Forbidden」表示服务器禁⽌访问资源,并不是客户端的请求出错。 「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以⽆法提供给客户端。
5xx:表示客户端请求报⽂正确,但是服务器处理时内部发⽣了错误,属于服务器端的错误码。 「500 Internal Server Error」与 400 类型,是个笼统通⽤的错误码,服务器发⽣了什么错误,我们并不知道。 「501 Not Implemented」表示客户端请求的功能还不⽀持,类似“即将开业,敬请期待”的意思。 「502 Bad Gateway」通常是服务器作为⽹关或代理时返回的错误码,表示服务器⾃身⼯作正常,访问后端服务器发⽣错误。 「503 Service Unavailable」表示服务器当前很忙,暂时⽆法响应服务器,类似“⽹络服务正忙,请稍后重试”。
GET 和 POST 的区别? Get ⽅法的含义是请求从服务器获取资源,这个资源可以是静态的⽂本、⻚⾯、图⽚视频等。 POST ⽅法则是相反操作,它向 URI 指定的资源提交数据,数据就放在报⽂的 body ⾥。
GET 和 POST ⽅法都是安全和幂等的吗? 在 HTTP 协议⾥,所谓的「安全」是指请求⽅法不会破坏服务器上的资源,「幂等」意思是多次执⾏相同操作结果都相同。 那么很明显 GET ⽅法就是安全且幂等的,因为它是只读操作,⽆论操作多少次,服务器上的数据都是安全的且每结果都相同。 因为POST 是新增或提交数据的操作,会修改服务器上的资源,所以不安全,且多次提交数据就会创建多个资源所以不是幂等的。
2.1.3 HTTP 特性
HTTP(1.1) 的优点有哪些,怎么体现的?
简单:HTTP 基本的报⽂格式就是 header + body ,头部信息也是 key-value 简单⽂本的形式,易于理解和使用
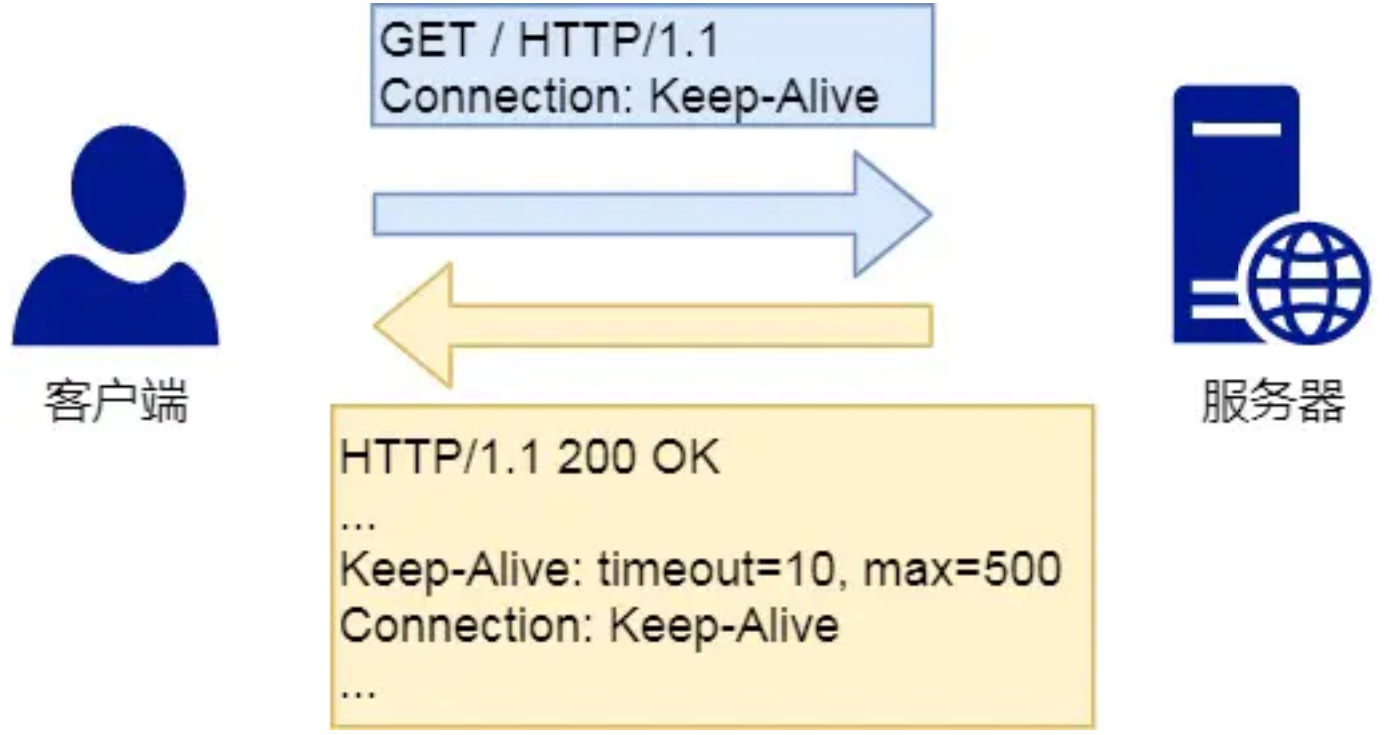
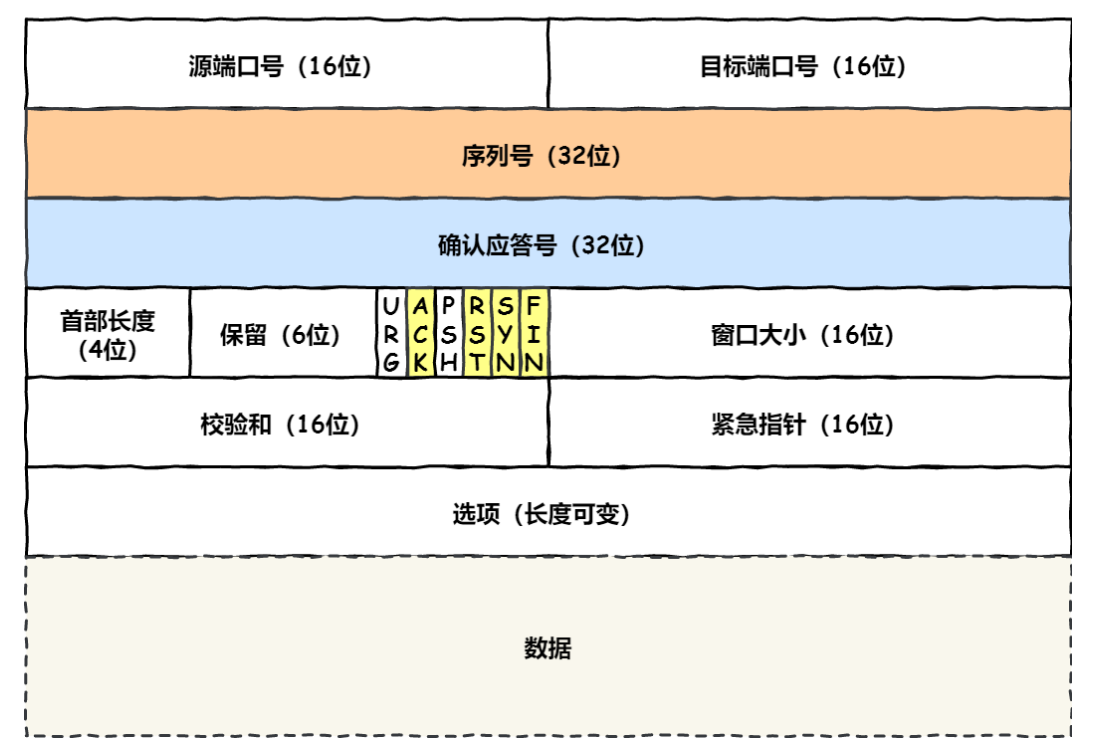
管道⽹络传输:HTTP/1.1 采⽤了⻓连接的⽅式,这使得管道(pipeline)⽹络传输成为了可能。即可在同⼀个 TCP 连接⾥⾯,客户端可以发起多个请求,只要第⼀个请求发出去了,不必等其回来,就可以发第⼆个请求出去,可以减少整体的响应时间。 但是服务器还是按照顺序,先回应 A 请求,完成后再回应 B 请求,可能导致「队头堵塞」。
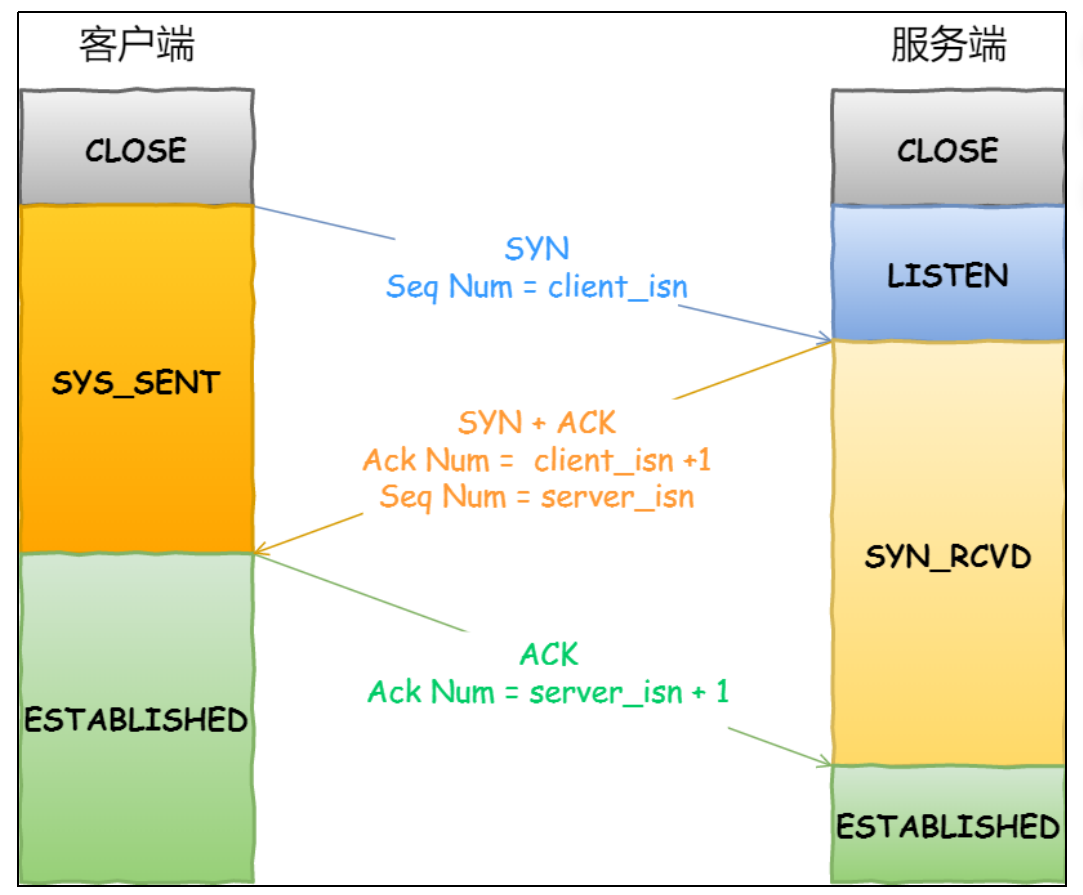
服务器收到客户端的应答报⽂后,也进⼊ ESTABLISHED 状态。⼀旦完成三次握⼿,双⽅都处于 ESTABLISHED 状态,此时连接就已建⽴完成,客户端和服务端就可以相互发送数据了。
3.2 TCP 重传、滑动窗口、流量控制、拥塞控制(小林p?)
-
3.3 TCP 实战抓包分析(小林p?)
-
3.4 TCP 半链接队列和全连接队列(小林p?)
-
3.5 TCP 内核参数(小林p?)
-
四、IP
4.1 IP基础知识
4.1.1 IP 基本认识(p314
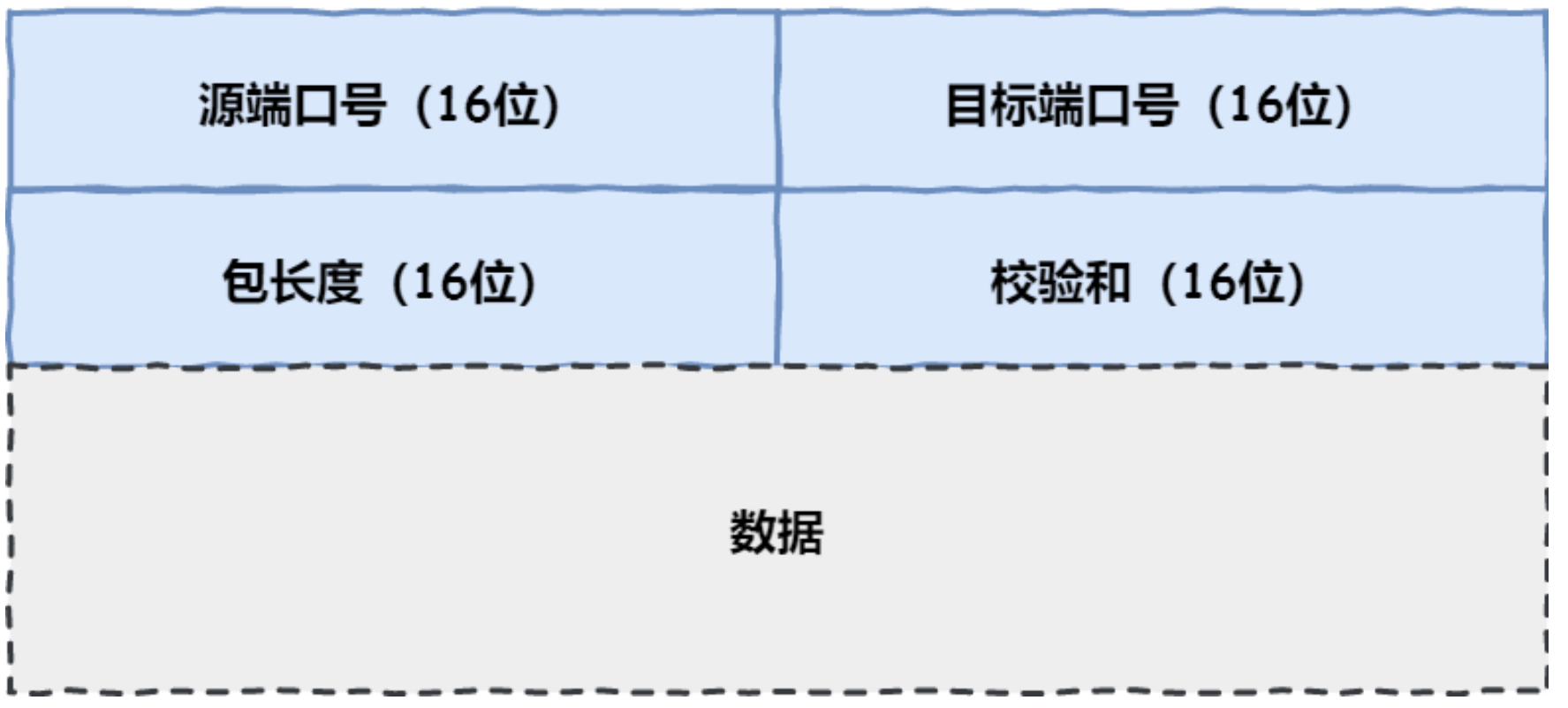
⽹络层的主要作⽤是:实现主机与主机之间的通信,也叫点对点(end to end)通信。 IP 的作用是在复杂的网络环境中将数据包发送给最终目的主机。
⽹络层与数据链路层有什么关系呢? IP 的作⽤是主机之间通信⽤的,⽽ MAC 的作⽤则是实现「直连」的两个设备之间通信,⽽ IP 则负责在「没有直连」的两个⽹络之间进⾏通信传输。
如果⼩林只有⾏程表⽽没有⻋票,就⽆法搭乘交通⼯具到达⽬的地。相反,如果除了⻋票⽽没有⾏程表,恐怕也很难到达⽬的地。因为⼩林不知道该坐什么⻋,也不知道该在哪⾥换乘。因此,只有两者兼备,既有某个区间的⻋票⼜有整个旅⾏的⾏程表,才能保证到达⽬的地。与此类似,计算机⽹络中也需要「数据链路层」和「⽹络层」这个分层才能实现向最终⽬标地址的通信。
还有重要⼀点,旅⾏途中我们虽然不断变化了交通⼯具,但是旅⾏⾏程的起始地址和⽬的地址始终都没变。其实,在⽹络中数据包传输中也是如此,源IP地址和⽬标IP地址在传输过程中是不会变化的,只有源 MAC 地址和⽬标 MAC ⼀直在变化。
4.1.2 IP 地址的基础知识
在 TCP/IP ⽹络通信时,为了保证能正常通信,每个设备都需要配置正确的 IP 地址,否则⽆法实现正常的通信。 IP 地址(IPv4 地址)由 32 位正整数来表示,IP 地址在计算机是以⼆进制的⽅式处理的。⽽⼈类为了⽅便记忆采⽤了点分⼗进制的标记⽅式,也就是将 32 位 IP 地址以每 8 位为组,共分为 4 组,每组以「 . 」隔开,再将每组转换成⼗进制。
那么,IP 地址最⼤值是 2^32,也即最⼤允许 43 亿台计算机连接到⽹络。
实际上,IP 地址是以⽹卡数来配置的。像服务器、路由器等设备都是有 2 个以上的⽹卡,是会有 2 个以上的 IP 地址;更何况 IP 地址是由「⽹络标识」和「主机标识」这两个部分组成的,所以实际能够连接到⽹络的计算机个数更是少了很多。
根据⼀种可以更换 IP 地址的技术 NAT ,使得可连接计算机数超过 43 亿台。
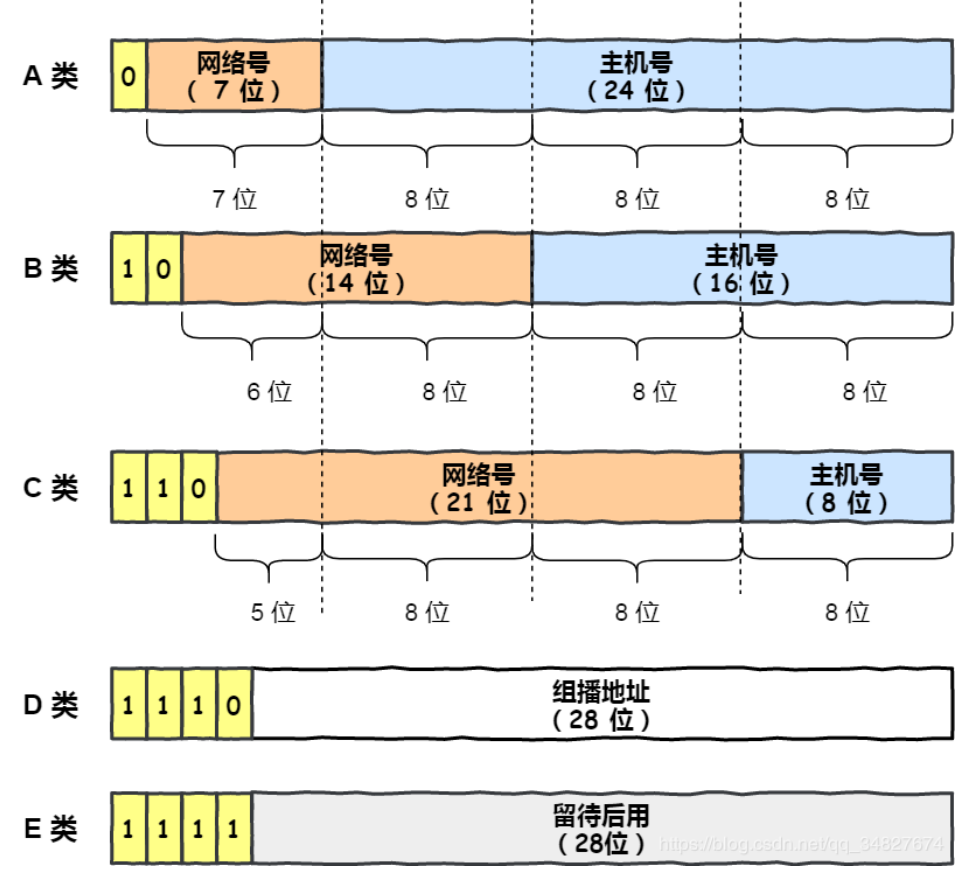
IP 地址的分类 互联⽹诞⽣之初,IP 地址显得很充裕,于是科学家们设计了 5 种分类地址,分别是 A 类、B 类、C 类、D 类、E 类。 下图中⻩⾊部分为分类号,⽤以区分 IP 地址类别
什么是 A、B、C 类地址? ??p318
4.1.3 IP 协议相关技术(p340
DNS 域名解析 域名⽅便⼈类记忆,使用 DNS 域名解析将域名⽹址⾃动转换为具体的 IP 地址。
域名的层级关系 DNS 中的域名都是⽤句点来分隔的,⽐如 www.server.com ,这⾥的句点代表了不同层次之间的界限。 在域名中,越靠右的位置表示其层级越⾼,层级关系类似⼀个树状结构:根 DNS 服务器、顶级域 DNS 服务器(com)、权威 DNS 服务器(server.com)
根域的 DNS 服务器信息保存在互联⽹中所有的 DNS 服务器中。这样⼀来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。因此,客户端只要能够找到任意⼀台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再⼀路顺藤摸⽠找到位于下层的某台⽬标 DNS 服务器
域名解析的⼯作流程
客户端⾸先会发出⼀个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端 的 TCP/IP 设置中填写的 DNS 服务器地址)。
本地域名服务器收到客户端的请求后,如果缓存⾥的表格能找到 www.server.com, 则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“⽼⼤, 能告诉我 www.server.com 的 IP 地址吗?” 根域名服务器是最⾼层次的,它不直接⽤于域名解析,但能指明⼀条道路。
根 DNS 收到来⾃本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com 区域管 理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
本地 DNS 收到顶级域名服务器的地址后,发起请求问“⽼⼆, 你能告诉我 www.server.com 的 IP 地址吗?”
顶级域名服务器说:“我给你负责 www.server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
本地 DNS 于是转向问权威 DNS 服务器:“⽼三,www.server.com 对应的IP是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
对 URL 进⾏解析之后,浏览器确定了 Web 服务器和⽂件名,接下来就是根据这些信息来⽣成 HTTP 请求消息了。
5.1.2 真实地址查询 —— DNS
通过浏览器解析 URL 并⽣成 HTTP 消息后,需要委托操作系统将消息发送给 Web 服务器。 但在发送之前,还有⼀项⼯作需要完成,那就是查询服务器域名对应的 IP 地址,因为委托操作系统发送消息时,必须提供通信对象的 IP 地址。所以,有⼀种服务器就专⻔保存了 Web 服务器域名与 IP 的对应关系,它就是 DNS 服务器。 使用 DNS 域名解析将域名⽹址⾃动转换为具体的 IP 地址。
5.1.3 指南好帮⼿ —— 协议栈(p379
???
5.1.4 可靠传输 —— TCP
-
5.1.5 远程定位 —— IP
TCP 模块在执⾏连接、收发、断开等各阶段操作时,都需要委托 IP 模块将数据封装成⽹络包发送给通信对象
/** * Exclude specific auto-configuration classes such that they will never be applied. * @return the classes to exclude */ Class<?>[] exclude() default {};
@RequestBody:用于将请求体中的数据绑定到控制器方法的参数上,通常用于接收 JSON 或 XML 数据。 @ResponseBody: 表示方法返回的对象应该直接写入HTTP响应体,而不是通过视图解析器进行渲染。
@Autowired 是 Spring 框架自带的注解用于进行依赖注入,将 Spring 托管的 bean 注入到需要它们的类中。 @Resource是 Java EE 提供的注解,用于实现依赖注入。它可以用于字段、setter 方法、构造函数等地方,用于告诉容器注入指定名称或类型的 bean。 @Bean: 用于定义Spring Bean,通常在 @Configuration 类中使用。 @Component 是 Spring 框架中用于声明一个类为 Spring 管理的组件(Bean)的注解。
@Service、@Repository、@Controller:这些注解分别用于标记服务类、仓库类和控制器类,以便 Spring Boot 可以自动扫描并创建这些组件。都属于 @Component 的衍生注解,用于更明确地表示类的职责。



 1、从前端页面中收到JSON格式数据,后端接口中将其封装为一个VO对象;接口接收到VO对象后将其转换为DTO对象,并调用业务类方法对其进行处理;然后处理为PO对象,调用Dao接口连接数据库进行数据访问(查询、插入、更新等)2、后端从数据库得到结果后,根据Dao接口将结果映射为PO对象,然后调用业务类方法将其转换为需要的DTO对象,再根据前端页面实际需求,转换为VO对象进行返回。
1、从前端页面中收到JSON格式数据,后端接口中将其封装为一个VO对象;接口接收到VO对象后将其转换为DTO对象,并调用业务类方法对其进行处理;然后处理为PO对象,调用Dao接口连接数据库进行数据访问(查询、插入、更新等)2、后端从数据库得到结果后,根据Dao接口将结果映射为PO对象,然后调用业务类方法将其转换为需要的DTO对象,再根据前端页面实际需求,转换为VO对象进行返回。






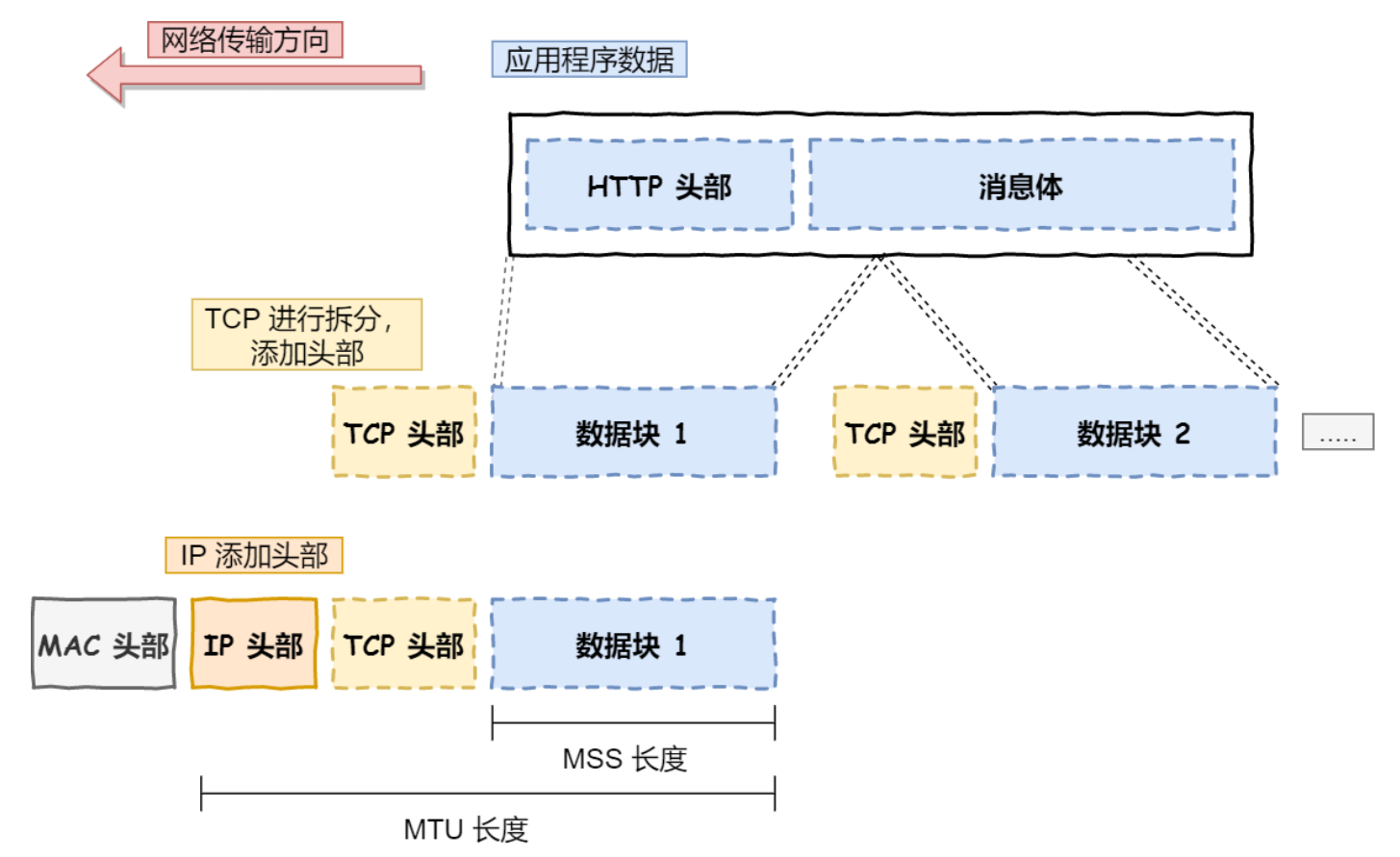
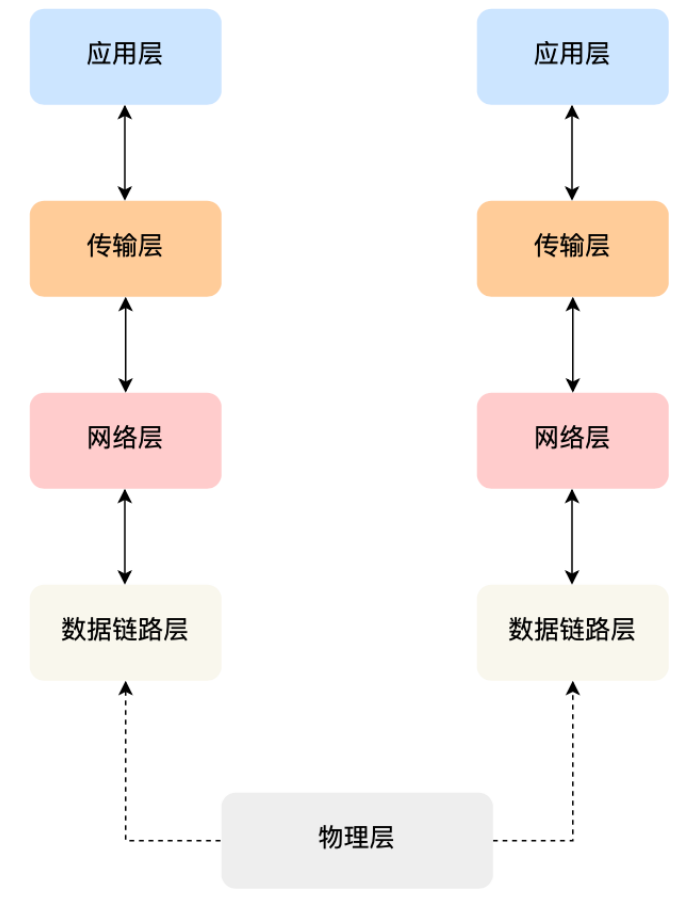
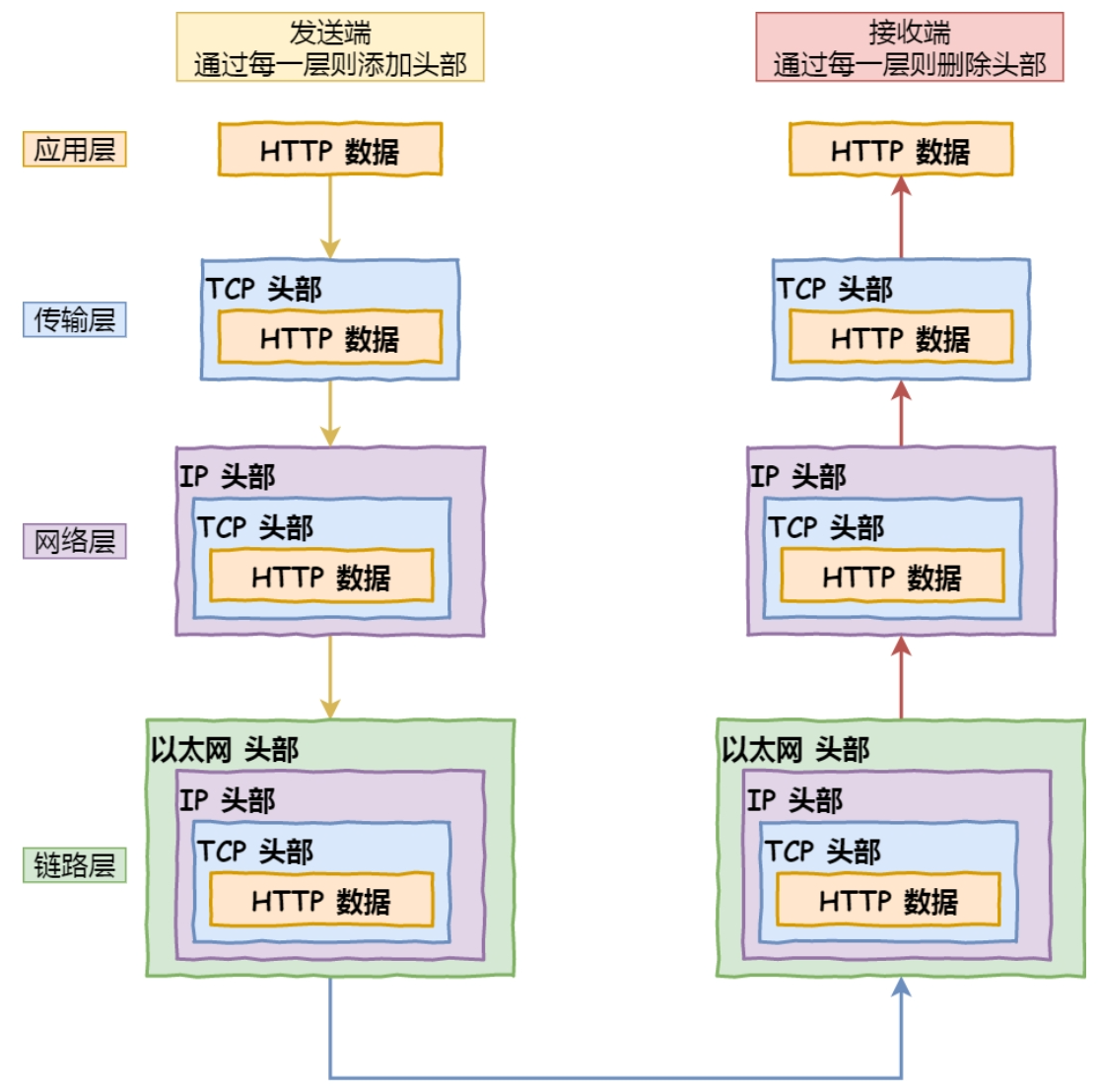
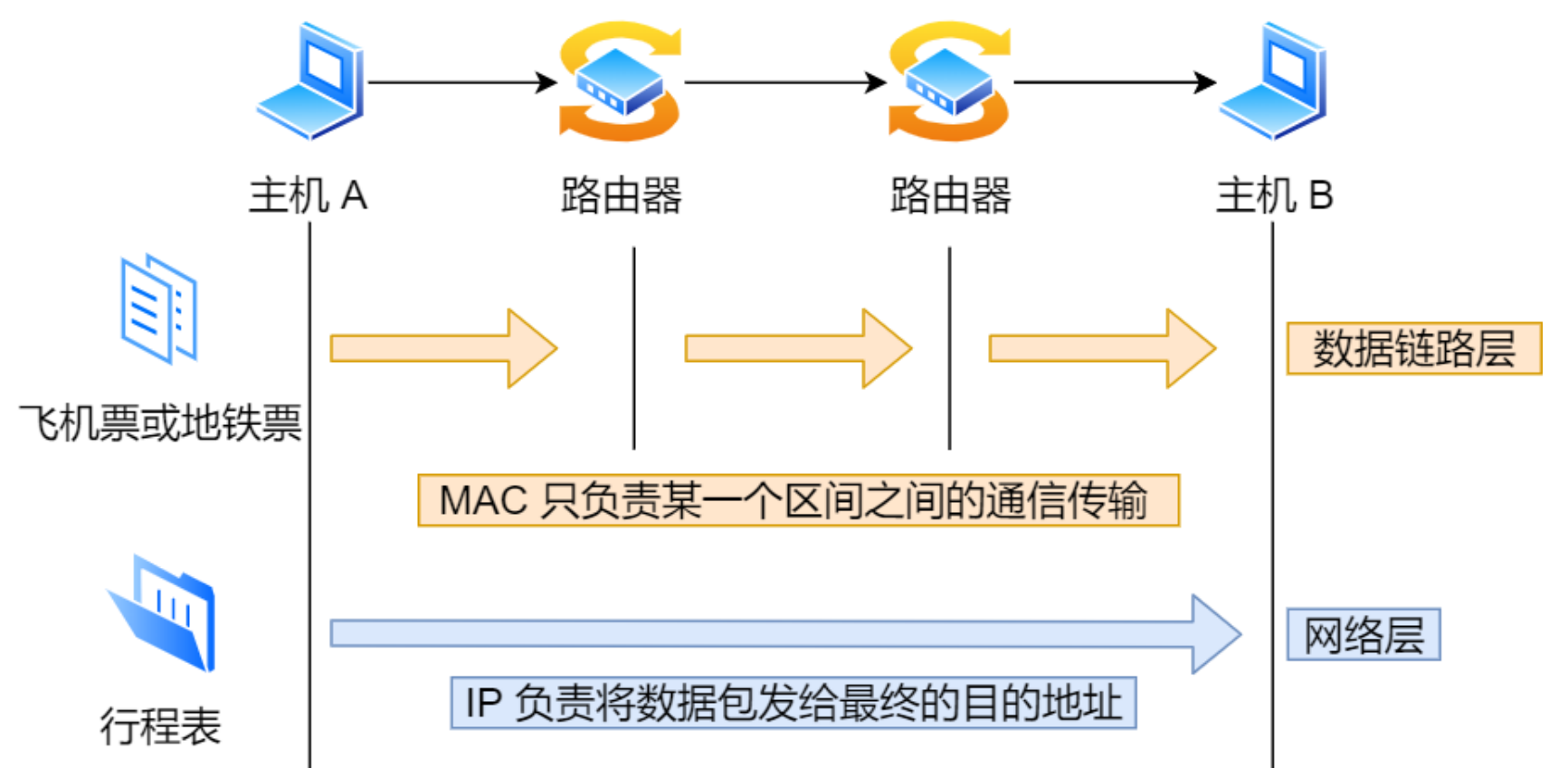 如果⼩林只有⾏程表⽽没有⻋票,就⽆法搭乘交通⼯具到达⽬的地。相反,如果除了⻋票⽽没有⾏程表,恐怕也很难到达⽬的地。因为⼩林不知道该坐什么⻋,也不知道该在哪⾥换乘。因此,只有两者兼备,既有某个区间的⻋票⼜有整个旅⾏的⾏程表,才能保证到达⽬的地。与此类似,计算机⽹络中也需要「数据链路层」和「⽹络层」这个分层才能实现向最终⽬标地址的通信。
还有重要⼀点,旅⾏途中我们虽然不断变化了交通⼯具,但是旅⾏⾏程的起始地址和⽬的地址始终都没变。其实,在⽹络中数据包传输中也是如此,源IP地址和⽬标IP地址在传输过程中是不会变化的,只有源 MAC 地址和⽬标 MAC ⼀直在变化。
如果⼩林只有⾏程表⽽没有⻋票,就⽆法搭乘交通⼯具到达⽬的地。相反,如果除了⻋票⽽没有⾏程表,恐怕也很难到达⽬的地。因为⼩林不知道该坐什么⻋,也不知道该在哪⾥换乘。因此,只有两者兼备,既有某个区间的⻋票⼜有整个旅⾏的⾏程表,才能保证到达⽬的地。与此类似,计算机⽹络中也需要「数据链路层」和「⽹络层」这个分层才能实现向最终⽬标地址的通信。
还有重要⼀点,旅⾏途中我们虽然不断变化了交通⼯具,但是旅⾏⾏程的起始地址和⽬的地址始终都没变。其实,在⽹络中数据包传输中也是如此,源IP地址和⽬标IP地址在传输过程中是不会变化的,只有源 MAC 地址和⽬标 MAC ⼀直在变化。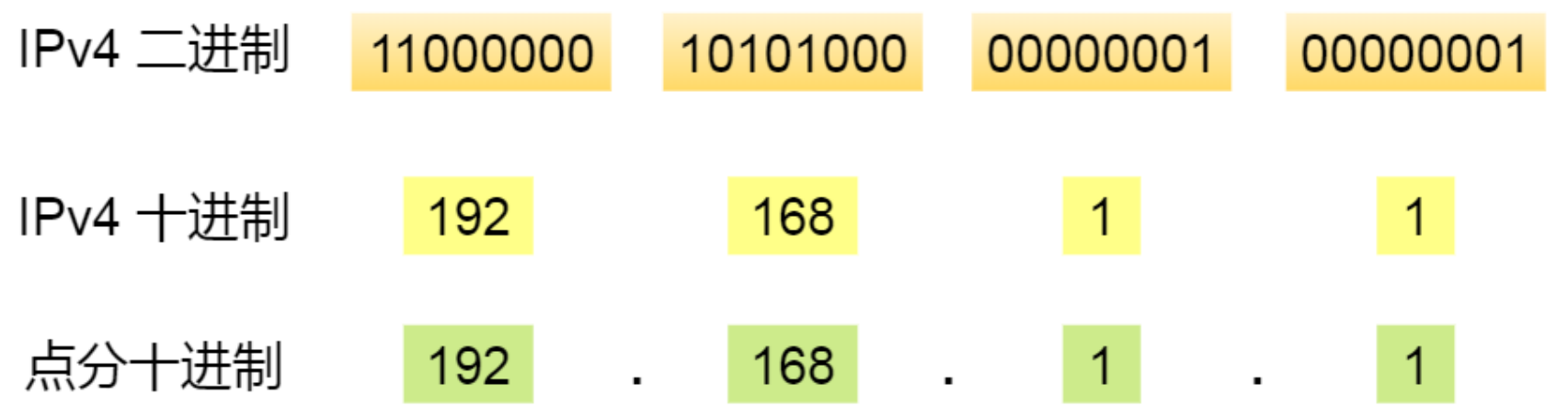 那么,IP 地址最⼤值是 2^32,也即最⼤允许 43 亿台计算机连接到⽹络。
实际上,IP 地址是以⽹卡数来配置的。像服务器、路由器等设备都是有 2 个以上的⽹卡,是会有 2 个以上的 IP 地址;更何况 IP 地址是由「⽹络标识」和「主机标识」这两个部分组成的,所以实际能够连接到⽹络的计算机个数更是少了很多。
根据⼀种可以更换 IP 地址的技术 NAT ,使得可连接计算机数超过 43 亿台。
那么,IP 地址最⼤值是 2^32,也即最⼤允许 43 亿台计算机连接到⽹络。
实际上,IP 地址是以⽹卡数来配置的。像服务器、路由器等设备都是有 2 个以上的⽹卡,是会有 2 个以上的 IP 地址;更何况 IP 地址是由「⽹络标识」和「主机标识」这两个部分组成的,所以实际能够连接到⽹络的计算机个数更是少了很多。
根据⼀种可以更换 IP 地址的技术 NAT ,使得可连接计算机数超过 43 亿台。
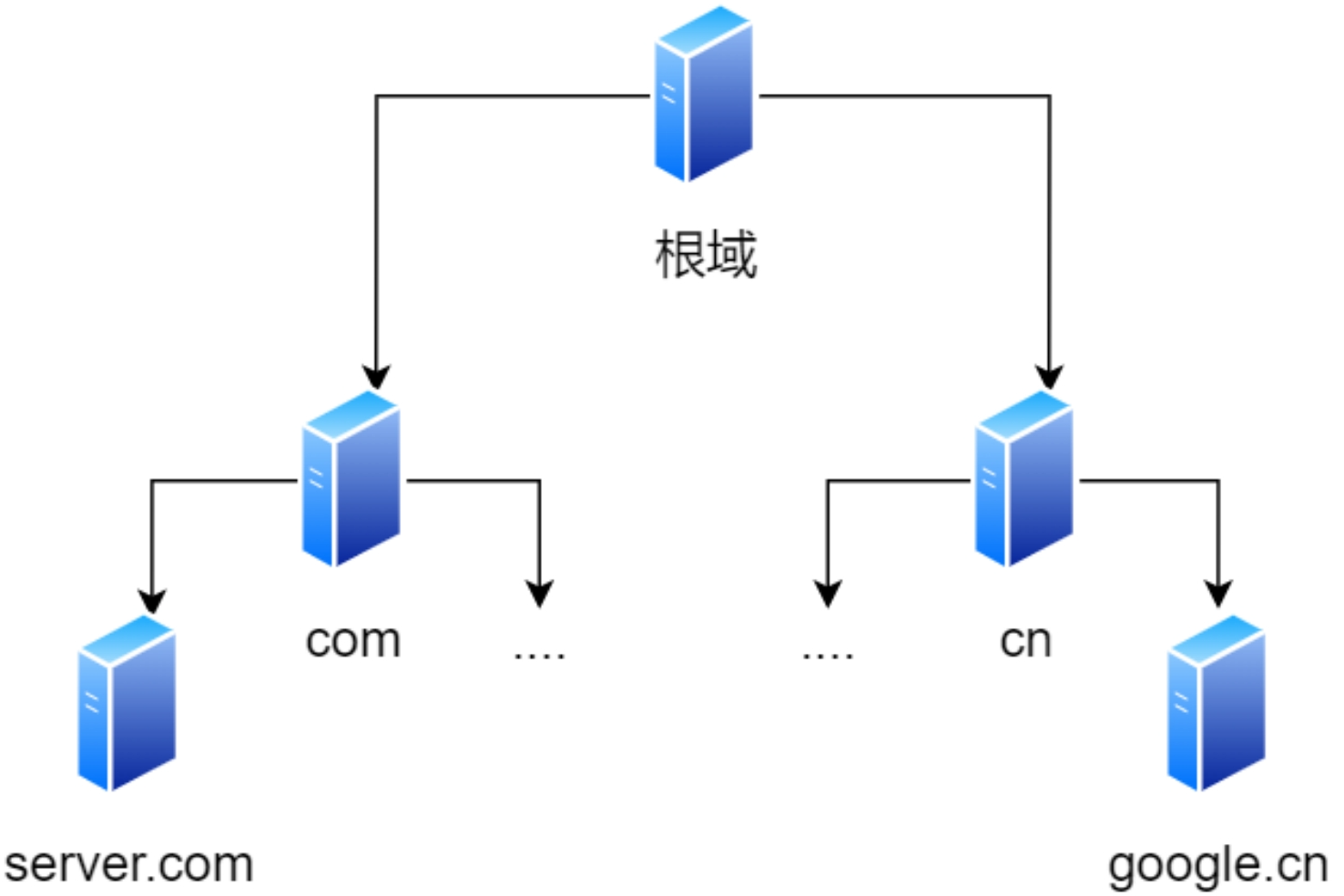 根域的 DNS 服务器信息保存在互联⽹中所有的 DNS 服务器中。这样⼀来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。因此,客户端只要能够找到任意⼀台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再⼀路顺藤摸⽠找到位于下层的某台⽬标 DNS 服务器
根域的 DNS 服务器信息保存在互联⽹中所有的 DNS 服务器中。这样⼀来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。因此,客户端只要能够找到任意⼀台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再⼀路顺藤摸⽠找到位于下层的某台⽬标 DNS 服务器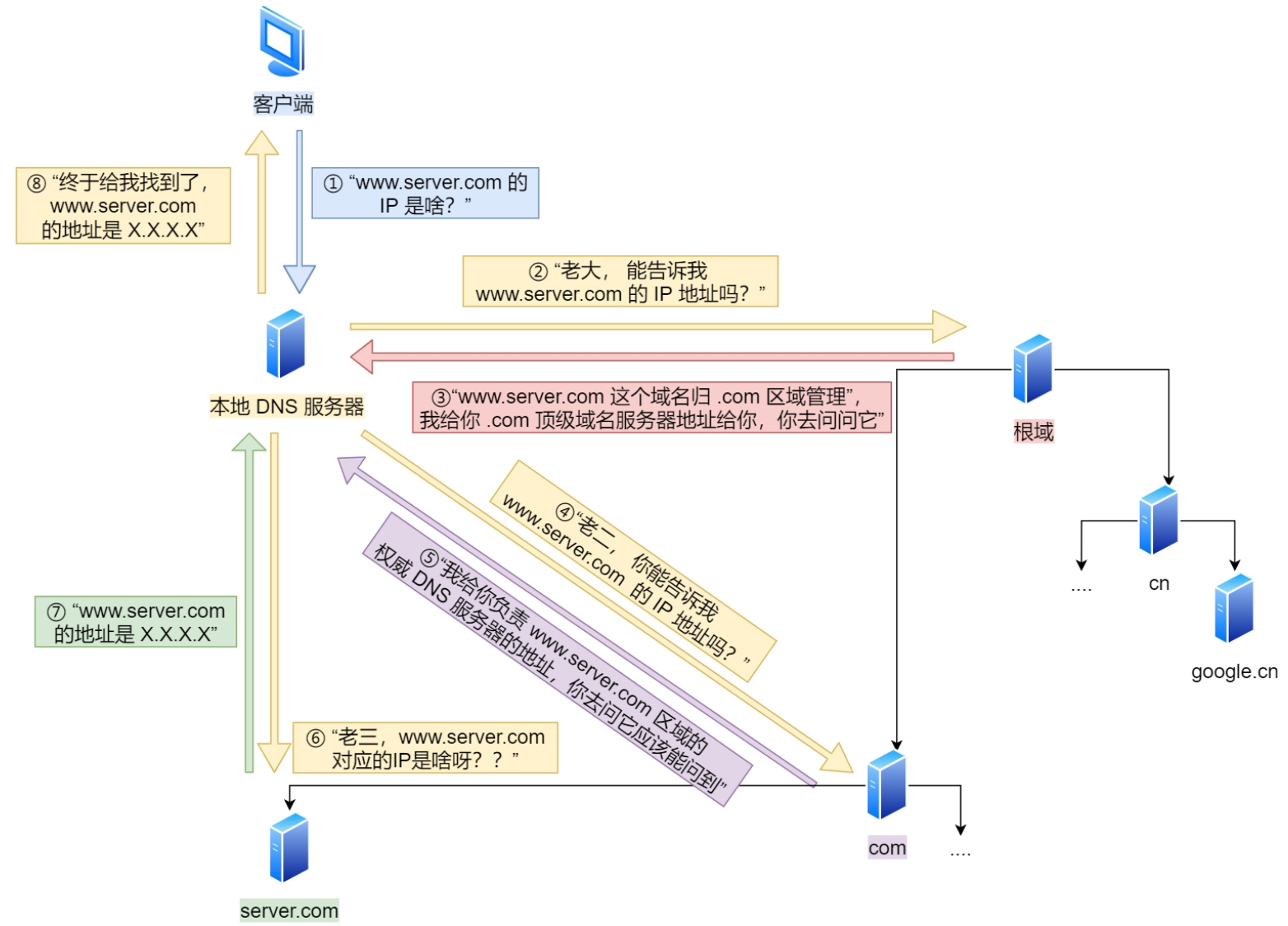
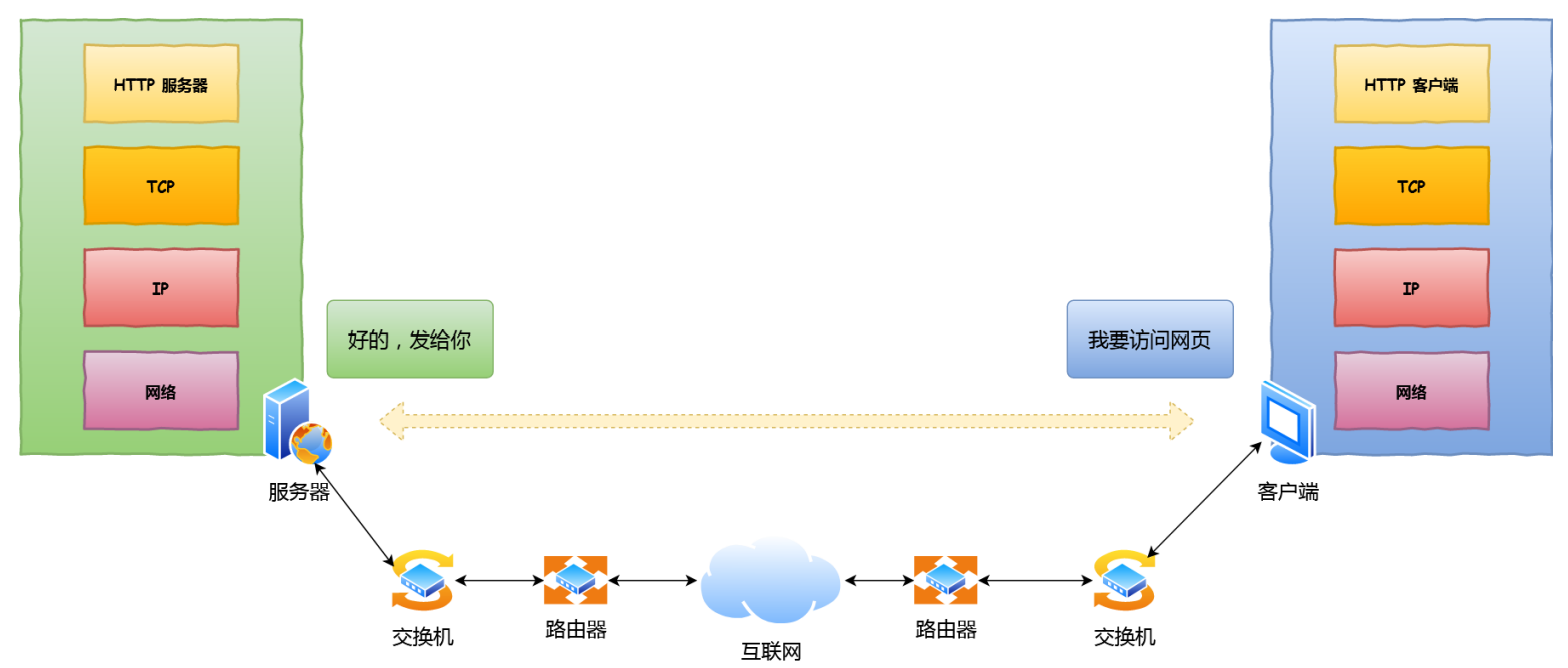
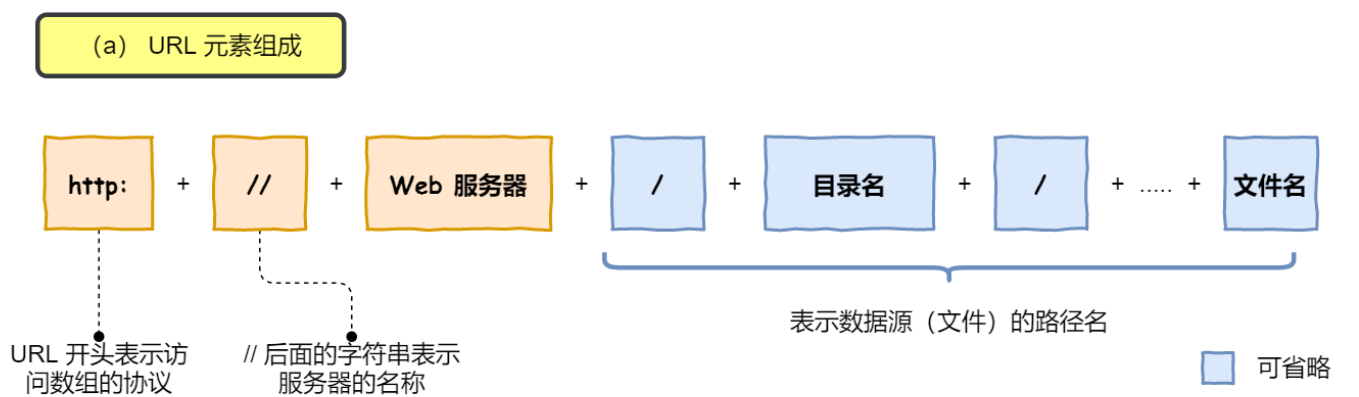 所以图中的⻓⻓的 URL 实际上是请求服务器⾥的⽂件资源。当没有文件路径名时,就代表访问根⽬录下事先设置的默认⽂件,也就是 /index.html 或者 /default.html 这些⽂件。
所以图中的⻓⻓的 URL 实际上是请求服务器⾥的⽂件资源。当没有文件路径名时,就代表访问根⽬录下事先设置的默认⽂件,也就是 /index.html 或者 /default.html 这些⽂件。