




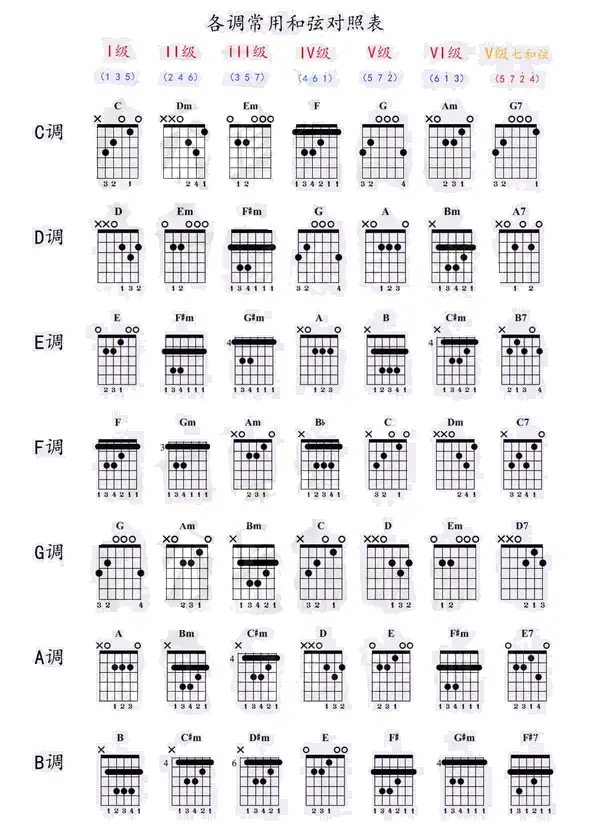
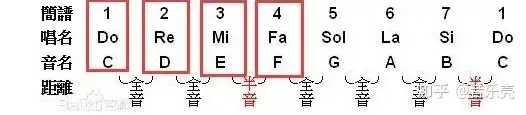
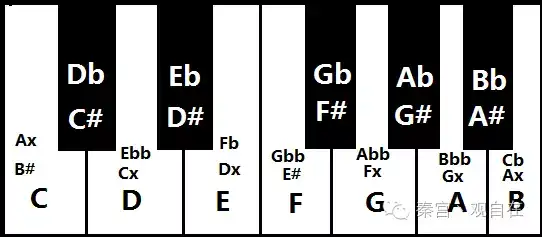
C大调音阶在吉他指板上可以有不同的把位 https://www.zhihu.com/tardis/zm/art/496745355?source_id=1005
扫弦节奏型:1)下 下 下上 上下上下 下上
节拍
HUB GUITAR: https://hubguitar.com/zh_han/music-theory 指板: https://hubguitar.com/zh_han/fretboard
弹奏第一品位上的B弦,这就是 C音,一个以一定频率振动的音波。接下来你拨第十三品的同一根弦,同样地,它听上去好像是同一个音,但这个音高更高。这是因为声波的振动是原来的两倍之快,可以表达为1:2, 它们是有同一特性的音。如果两种不同的乐器同时弹奏C音,这个比例是1:1,这称为 同音。在下图中,第一品的音符将会是最左边的C,第十三品的音则是在最右边。所有在这两者之间的音符都是特定的音符,但一旦重新回到C音,就重新按照这个顺序继续下去。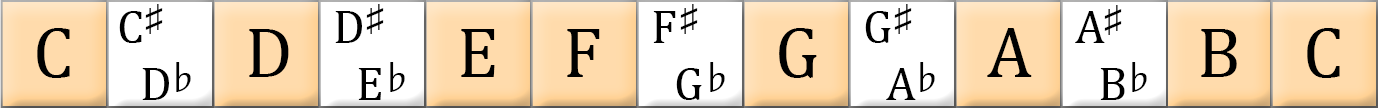
音程:就是两个音符之间的高低关系。在较低的一个 “C” 音和另一个较高的 “C” 音之间的音程就是 八度(八音音阶)。八度是音高的基本来源,其余的还包括将它分成更小的部分而得到的音高,称为 音数。半音就是移动一格,从 C 到 C♯。全音移动两格,从 C 到 D。 大多数现代音乐将八度分割为12级,如图所示,你可以按照这个音符的顺序来弹奏,从第一品的 B 弦开始,每次移动一个品位,直到第十三品,重新回到 C,一边弹奏一边大声说出这个音符的名字。所有这十二个音符一起组成了 半音音阶。音阶就是音符的顺序,并且没有重复的音符,所有的音符以升序,从低到高的顺序来弹奏。
根音?它就是一首歌的主调音,它是一个单音,其余的东西全在它的基础上变化,想像它是重力中心,它是一种吸引力,吸引着一首歌曲里其余所有的音,不管什么情况下都会回到根音上来。
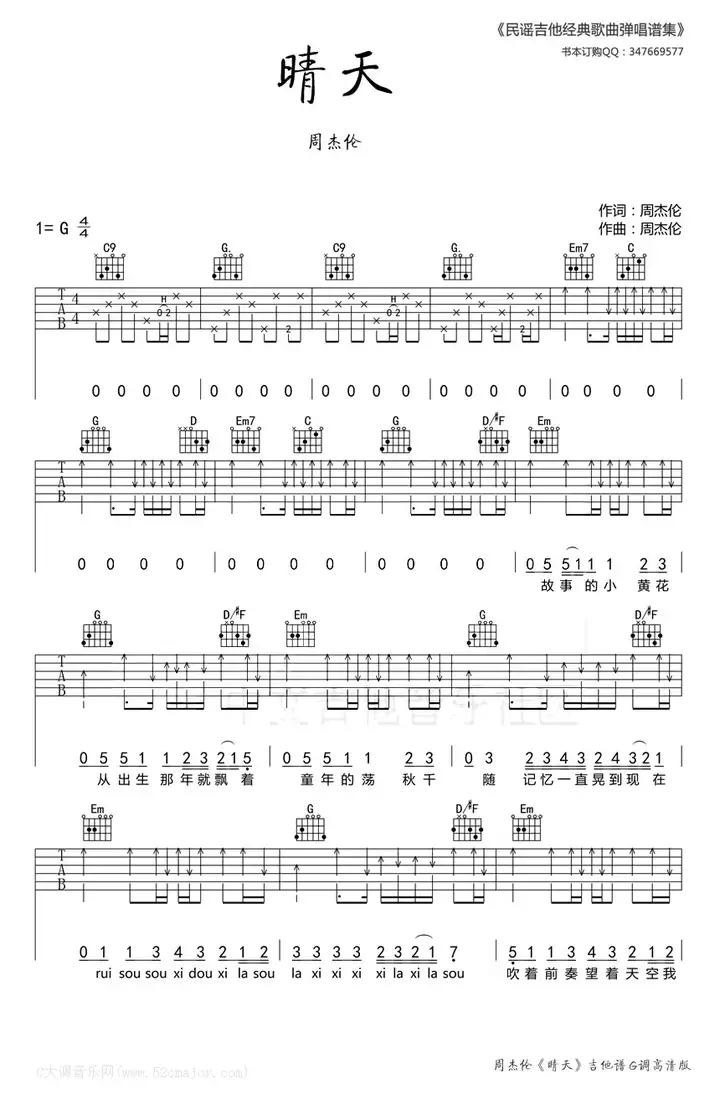


晴天 - 周杰倫



Hey Jude - The Beatles



紅豆 - 方大同
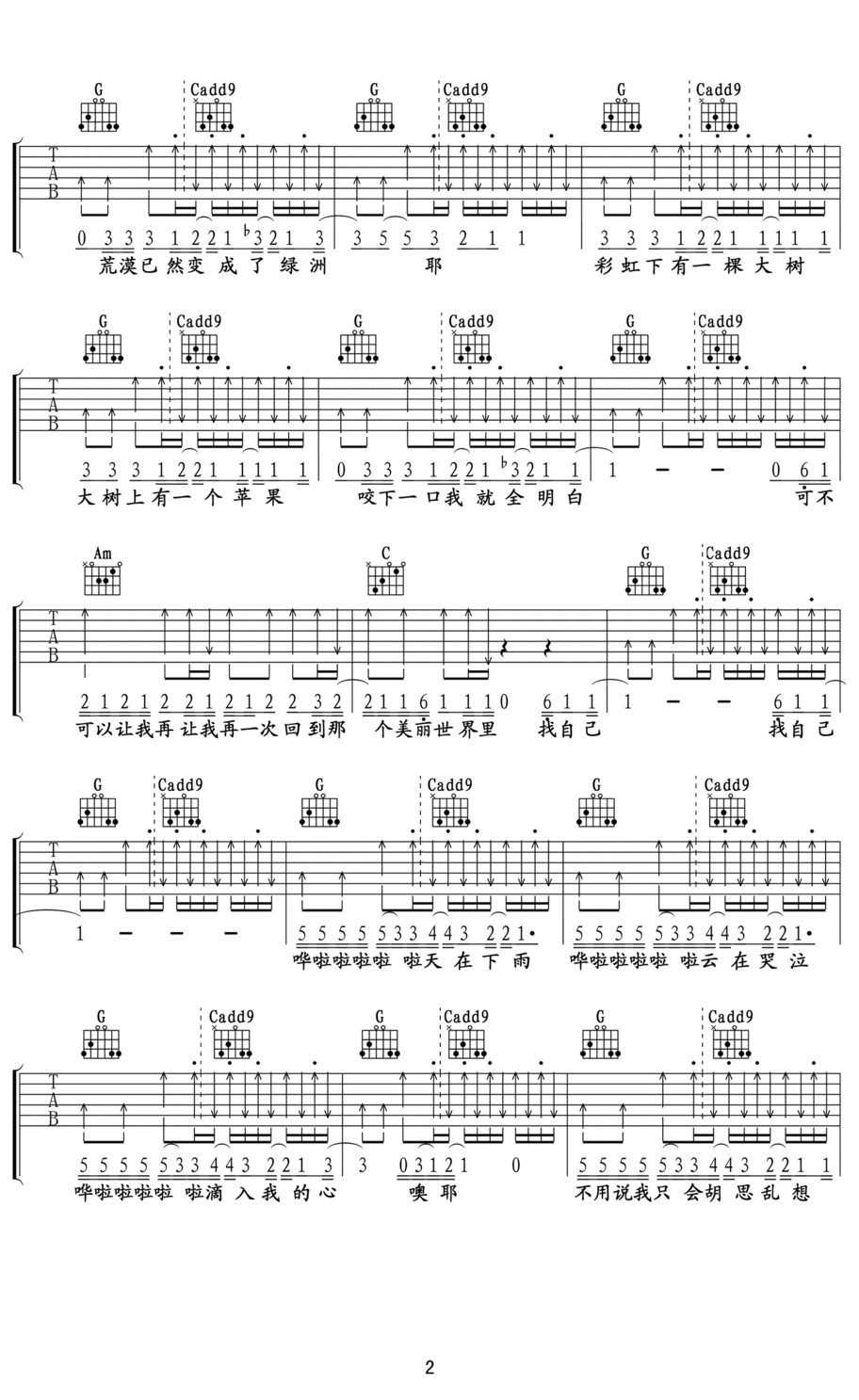
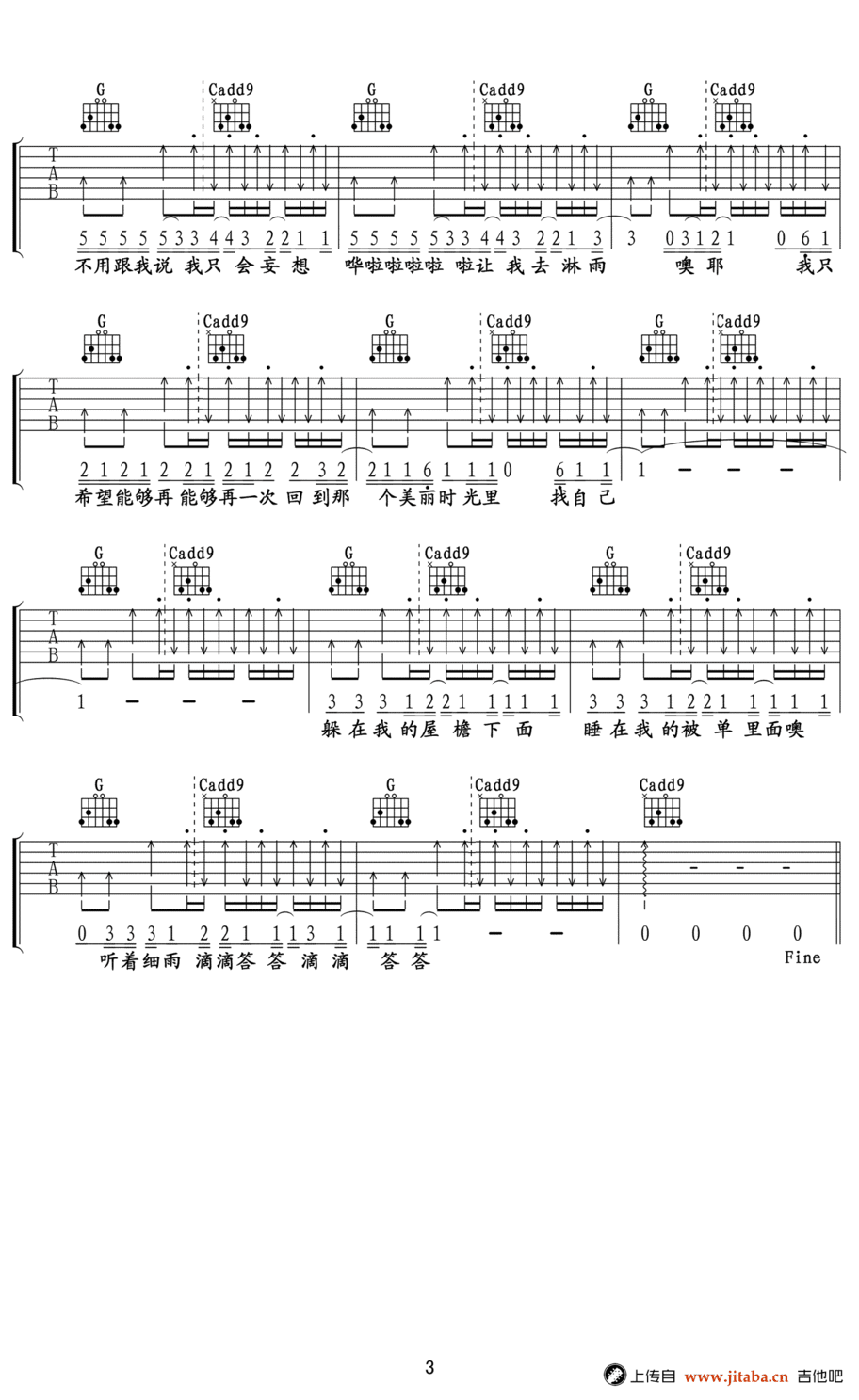
找自己 - 陶喆

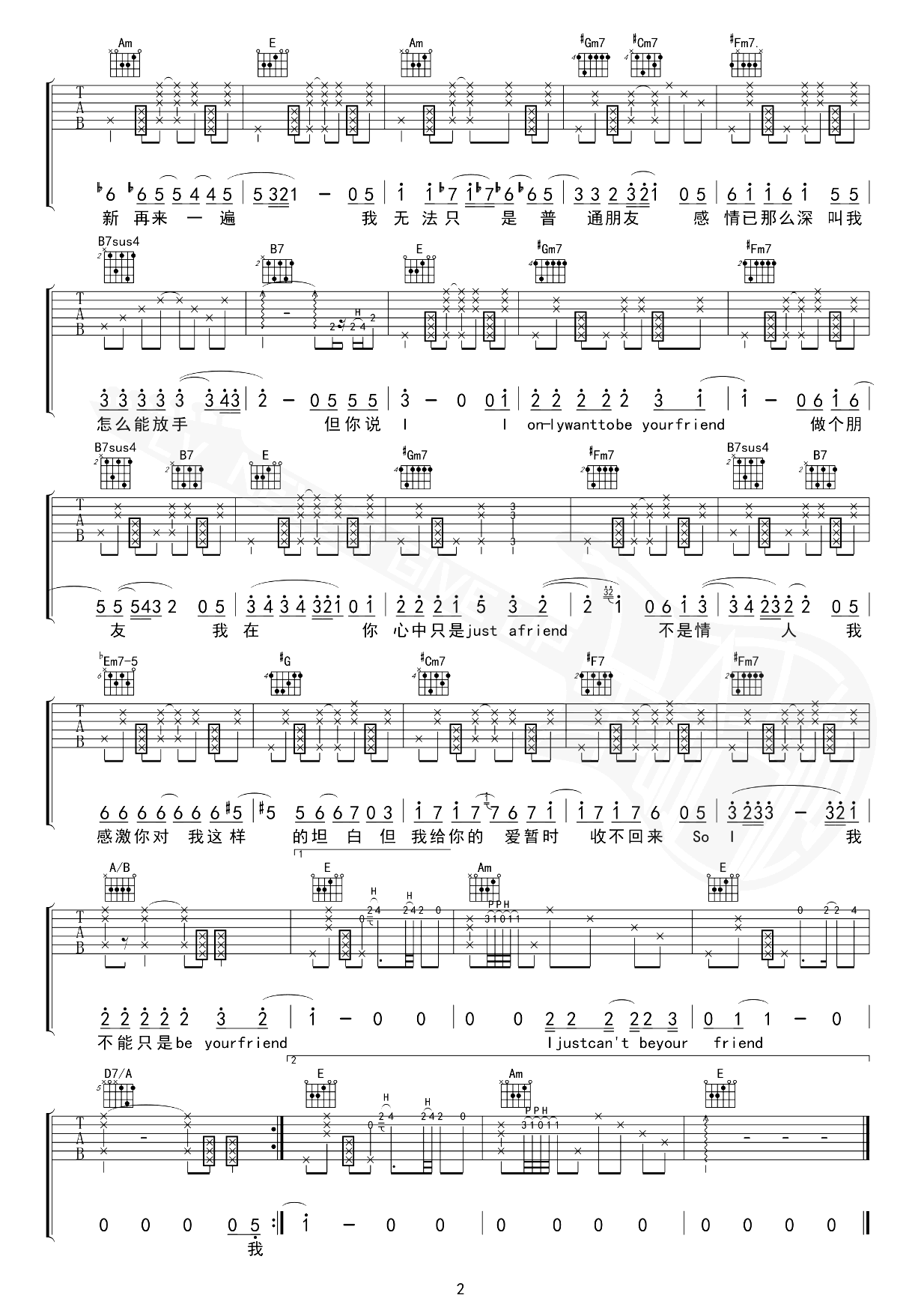

Canon in C https://www.bilibili.com/video/BV1if4y1A7SZ/


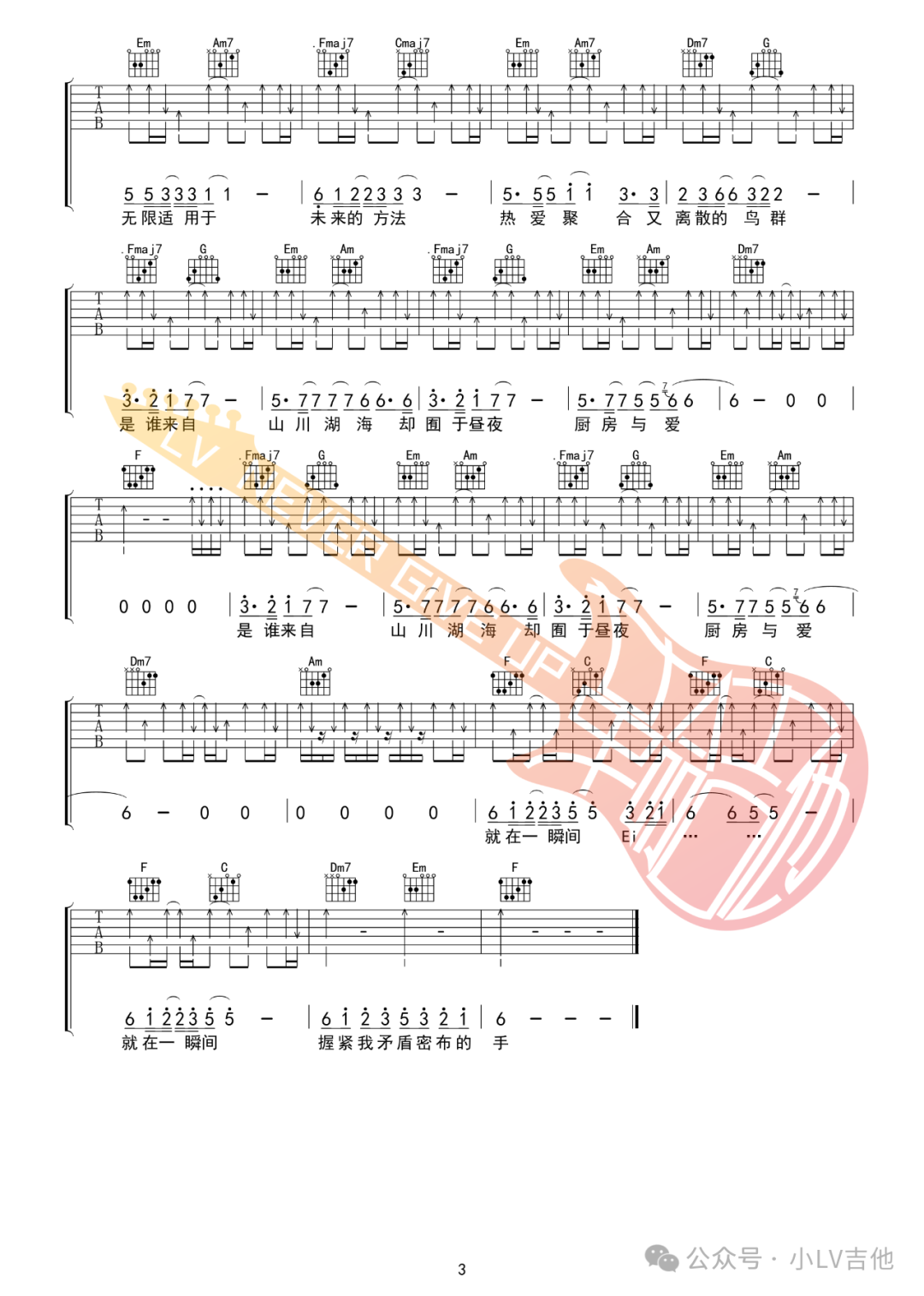
揪心的玩笑與漫長的白日夢 - 萬能青年旅店
https://www.bilibili.com/video/BV1cuHjetENY/?vd_source=ff210768dfaee27c0d74f9c8c50d7274

入职第一天,熟悉运维平台,目标实现其自动化,后续参与到美的云,?
熟悉新旧平台的功能和调用关系,拆分业务需求开发步骤,编写文档,每日汇报进展,熟悉开发流程、、
软工院作为非互联网公司的非核心业务的底层平台建设部门,结果导向,组员多一年社招;)无校招培养。?
EDP培训 + MGC(头脑风暴/产品调研/拉通对齐>>技术)
T型人才(广度+深度),开发技术+产品思维->架构师
不设限,主动承担任务,机会莫名来:) take other people’s jobs and become indispensable to the team..
复杂的事情简单化(思考简化),简单的事情复杂化(做到极致)
工作就是生活,生活就是工作,不需要平衡(找到热爱的工作)
成功的百分比 = 做事 / (个人 + 做事);做事的比例越大,成功的概率越大
Allen: 向上管理?× 向上反馈,同步进展
MGC结营
融入团队?主动承担?谈论未知?如何选择自己在团队中的角色,人设??
圈子
佛山校友会迎新
“努力会发光,先有为后有位”,“头三年不要动,把这一套学会”
程序员的本质核心竞争力是什么?1.开发都是那一套 2.专精一个领域 3.meet新公司的需求 4.解决问题的能力
华为云主机开/关机/重启自动化 : mq、定时任务、公有云api、crud、、
完成第一版8.14,自测8.15,,merge request,code review,sit,测试,uat,发版8.22、、
反思、、在开发同事的指导下完成了开发,不具备独立调研和开发能力,,
缺少对产品的思考??没有对需求进行120%的思考和完成。。
顺德校友会迎新
why Midea?1.生活成本低(特别是住宿好通勤方便)2.相比下工作轻松(能够有自己的时间学习业务以外的东西)
思考自己在..年后会到什么层次(本科毕业+6y ?= 博士毕业起步)。。阶段性目标
深入一个领域,,
先做一点功能点,然后负责一个模块,到不同系统的交互、、
多学基础,与外包的区别。。与人沟通的能力
幂等,整体设计,微服务治理,看项目源码,,
干半年就不是应届生了。社会很残酷,前两年要快速成长;思考两/五年后的情况、、
开发整个过一遍,打包,发版,,
多讨论,多问,code review
失败邮件发送:设计一个功能,,关注点,逻辑路径,通用性,,如何表述。。?! –>
方法:事务+行锁【悲观锁】,避免在高并发场景下先读后写导致多个线程同时读取相同的值然后同时写入引发数据不一致的问题
测试:线程池多线程访问,打印数据,排查重复值;考虑数据库连接池配置
思考:项目部署到多节点下,则是多进程的多线程环境,需要用Redis分布式锁,或者唯一的全局数据库节点加锁;
单节点的多线程才能用synchronized?、
1 |
|
1 |
|
优势:完全避免了并发更新导致的数据不一致,是标准的悲观锁实现。
潜在问题:如果方法被高频调用,FOR UPDATE可能导致锁竞争,影响并发性能。
更优方案:直接 UPDATE + SELECT
Azure公有云主机申请 :根据云管界面配置配齐参数发送报文到作业平台,完成自动化主机创建和标准化
对其参数,连续加班,9.9完成第一版,9.10上sit前端联调,9.11开发部分发邮件,9.12上uat,6.同步DDL&DML,7.发版,验收成功
接触运维协同,,code review,联调,,集成,部署,流水线,,
窝囊费:)到账
Azure公有云主机回收/开/关机/重启 : 调研AzureApi和测试方法,开发,,
9.23回收上sit,9.24开关机重启代码重构(原华为云方法过于不通用),9.25bug毁了我的足球梦,9.26配置ngix上uat,验收
思考:自测可以 1.全流程验证 2.单独功能验证 3.考虑开发与测试环境的区别(ping的包装方法/命令行执行在开发/测试环境的区别)
后续:完善公有云开发(Azure回收配额,ip,失败邮件),后续由运维平台MOPS -> 参与到数据库开发
任务触发式失败邮件完成,改造为工单定时任务扫描式,10.17上线
邮件通用性??工单+定时任务层面的通用,,
数据管控平台DataMars: 云管cmcloud开发功能,先提供内部服务,后到SAAS,,
InfluxDB备份恢复 1 调研 2 手工实现 3 详细文档
2-3月时间,不要求11月上线,整体设计,转正答辩
api,数据库内核,容器,k8s
容器,登录主机,查看docker实例,操作数据库实例
1 | ~$ sudo su - apps |
influxdb 命名空间下的所有 Stateful、Pod 的状态和节点信息1 | kubectl get sts -n influxdb |
influxdb 命名空间下的 service 信息。1 | kubectl get svc -n influxdb |
kubectl exec 进入指定的 Pod(默认进入其中的第一个容器),并启动一个 bash shell;可以看到当前 InfluxDB 版本是v1.8.10-c1.1.21 | apps@(datamars)mhpl74337-10.20.248.65 ~$ kubectl exec -it influxdb-e2cb6c913a191e56c134e-data-0 -n influxdb -- bash |
1 | root@influxdb-e2cb6c913a191e56c134e-data-0:/# influx |
1 | root@influxdb-e2cb6c913a191e56c134e-data-0:/# influx_inspect export -datadir "/var/lib/influxdb/data" -waldir "/var/lib/influxdb/wal" -out "influxdb_test01_dump_out" -database "test01" -start "2024-10-22T00:00:00Z" |
1 | sudo kubectl cp influxdb/influxdb-e2cb6c913a191e56c134e-data-1:/influxdb_test01_dump_out data/influxdb_test01_dump_out |
1 | kubectl get secrets -n influxdb # 看命名空间 |
1 | root@influxdb-e73f149ff7192bd87d190-data-1:/# influx -import -path='influxdb_test01_dump_out' -precision=ns -username='admin' -password='' |
-database,把influxdb集群实例中所有数据库的数据导出,加 -compress 导出压缩文件-compressed 导入压缩文件,本质上是先解压后倒入10.14-10.18:看文档,建立InfluxDB集群概念(前期已经也在看了..),建立整体框架概念(apiserver–bakserver–agent)
10.21-10.25:本地容器搭建influxdb集群×,连接服务器测试实例验证功能,了解K8S概念,手动验证实例(库级)导入导出即逻辑备份
10.28-11.01:对其需求(能做但没用户??),完成技术文档框架,开始将功能接入datamars-bakserver,了解golang开发
11.04-11.08:搭建go开发和agent项目环境,,无法理解go项目结构,尝试从bakserver侧理解task下发-接收-执行全流程
11.11:理解所有业务代码(after2weeks)发现task下发无需改动,只需适配influxdb(修改配置类和表),接着打包至sit环境打印log调试
11.12-11.15:研究pod添加container(改sts后delete pod重建),go项目构建(windows尝试配齐开发工具但有些包依赖linux环境)》。
11.18-11.27:本机wsl的ubuntu成功构建起datamars-agent,边抄边做,不用理解其框架?.. 及时请教专家
11.28-12.03:kun手改agent代码:)打包image push到dockerhub,宿主机拉取镜像后本地grpcurl调试 pod ip:port 验证功能
12.04-12.09:bakserver打日志流水线部署到uat(集群实例所在环境),通过apiserver-bakserver-agent中的日志验证全流程功能
12.10:验证通过
技术文档先行,将需求拆分成一步步,重要的是要有产出,,能汇报进度。。buffer。。好心态😇不怕叼
关注重要的事情(功能接入已有框架/理解业务逻辑×,功能验证和对齐需求√,开发卡点及时请教)
1/2时间幻想(串联已知信息且验证,对齐上下游并重复验证,本质是开发环境,业务不熟悉),1/4等回复(线上下请教+准备),1/4开发(快乐短暂)
与人沟通是重要的能力。。拉群问。。软件开发还是很残酷的。。
2025.04:重新考虑… 1 influx_inspect export只是把该pod指定数据库(或所有库)的指定时间段的分片数据(tsm&wal)导出line protocol文件,各Data-Pod数据不一致时不能代表整个实例;2 influx -import本质是将数据重新写入,前提要先恢复好shard元数据,,
1.02:不上心
1.14:开发uat自测(sit没测)完成,开发分支合dev提测,最后合main上线
1.16:SD/GA测试发版失败,恢复工作流需要人工介入验证,存在问题 1地址没有动态配置!! 2漏配接口/审批流变更
1.21:发布修复版本,生产延后
当前阶段的关键,,交付能力,,工程能力是练出来的
熬夜是没有对明天的期待、、-》培养兴趣转移注意力、,books
程序员。技术。不要只看自己的一亩三分地。。开源项目
工作以外;:给自己创造需求,根据需求解决问题,在解决问题上配合看书,,从而在某一细分领域有知识图谱,有一技之长,用系统性的看书代替cdsn查找零散的解决方案
“下班的时间放在哪哪里就有提升”
副业?;web3;licai
dataMars服务架构理解
todo 手画图
2.6-2.16:现有InfluxDB集群实例(只考虑data节点)的CPU、内存和存储资源已无法满足需求,需对资源配置进行扩展,以提升性能和稳定性。通过修改StatefulSet中cpu、memory配置并删除Pod触发StatefulSet控制器重建data节点Pod以应用新配置,通过修改data节点Pod对应的pvc中storage配置以触发pv的存储扩容(只能增加),实现资源变配(本地变配)
2.17:前端对齐开发,准备进入sit联调
2.18:插入需求“meta节点自定义创建”
2.28:整合已知信息已读代码->无法理解多节点类型实例如何发起变配,应该果断求助
3.3-3.10:改造influxdb集群为父子实例模式,改配置,传参调试,适配已有功能,考虑存量实例的影响
3.11-3.13:data变配基础上开发meta变配,云管订单遇到配额不匹配问题,上线延期下周
3.14:跨团队求助无果,请求协助,,新需求着手开发
3.17:搁置,开发新需求
3.18:实操tidb复现该“问题”,考虑转向与云管沟通。。
3.27:发版 =》InfluxDB父子实例改造/本地变配/节点/实例重启
读书时无所事事的日子,今天拔完牙和妈妈一起冰敷等待的日子,还有多少
刚开始普遍很难,易的是背八股,难的是落实和推进
如何跳出这个困境?如何跳出程序员行业?30岁,35岁
熬夜是因为没有对明天的渴望。但是在晚上的当下,有很多事情想做😿
喜欢一个人独处,是因为不想自己长期以来形成的情绪稳定被打破。害怕形成亲密关系,有时无法融入团体😿
2.18:本需求作为其他需求开发的前置条件
2.19:apisever打log上uat调试创建流程,从已部署分支git branch新分支以免影响正在使用者
2.21:提sql变更 1 dataspace提工单 2 直接进入各环境metadb(其本身为容器部署的mariadb服务) 3 某些配置项可通过datamars控制台修改
2.25:云管运营端商品信息变更,考虑是否影响存量实例;;1 云管释放旧实例将计价报错->调datamars管控接口释放/发版前释放旧实例 2 可以发起工单但无法下单->手动修改配额发起工单后过云管审批
2.27:发版流程、、代码合master,流水线打包使用(发版版本)部署,sql变更(定时,增加条件避免误订正),云运营变更(改一次console-cloud即各环境共用)
Steven👨🦲:裁员,残酷,危机感,,工作就是生活的很大一部分
deepseek:数据库方向是一个值得长期投入的领域,尤其适合对系统底层感兴趣的程序员。你的现有经验(运维+K8s)可成为切入云数据库或分布式数据库的跳板。建议以“运维需求驱动内核学习”为短期目标,逐步掌握分布式一致性、存储引擎等核心技术,同时通过开源贡献和项目实践构建技术影响力。=> https://yuanbao.tencent.com/bot/app/share/chat/c6b48985efa0c1101e5c6ae18c867724
rong teng:在midea得到的成长是显著的;(身兼开发运维多职,具体求职情况如何?)数据库方向有些窄;(作为senior求职需要专精时显得窄?作为基础能力学习可行?)应届生可以提转方向,转团队;以招聘市场心仪岗位的需求作为努力发展的方向!?
3.17:简单需求,父子workflow + k8s资源控制器
3.18:接口配置:接口信息查看mariadb已有的相同接口,其他信息参考influxdb自身的其他接口;前端联调完成
3.19:提测,发版:发版分支一周内进行 1 代码扫描-安全扫描 2 安全-软件成分-Web漏洞-灰盒,解决漏洞;代码仓库设置发版分支,史诗中关联所涉及仓库,检索其发版分支的扫描报告,手动关联web漏洞测试报告,质量门禁达标以通过安全卡点
1 | # 生成随机类名避免冲突 |
TEMP_JAVA="/tmp/${CLASS_NAME}.java")rm -f "$TEMP_JAVA")1 | System.out.println("USERNAME:" + username.trim()); |
1 | # 错误示例:初始方案采用`IFS`分割导致变量截断 |
1 | credentials=$(get_auth $1) # get_auth()动态生成java解密脚本并多行输出 |
1 | function select_data_pod() { |
| 方案 | 优点 | 缺点 |
|---|---|---|
| 文件存储 | 实现简单 | 存在安全风险 |
| 环境变量 | 进程内可见 | 长度受限 |
| 标准输出 | 无持久化风险 | 需严格格式控制 |
| 网络传输 | 适合分布式 | 增加复杂度 |
本项目完整代码已开源,读者可通过GitHub仓库获取最新版本。
3.28:需求分析->将pod迁移到集群的另一个资源充足的node上,并且恢复数据以及集群功能(元数据)
3.31-4.1:存量实例问题处理,, 建议客户使用改造后的influxdb实例,存量实例释放/启停/重启等功能遇到问题 =》未考虑好适配
4.2-4.7:出方案 1 sts指定亲合度规则以在指定node重建pod和pvc 2 开源influxdb-cluster功能不完全支持,考虑从分片副本层面恢复数据
4.8-4.10:数据恢复的主要思路=》从健康节点的分片副本copy-shard恢复出迁移节点原有的所有分片副本,?质疑->恢复过程中健康节点的分片副本持续写入的增量数据能否恢复??
4.11:考虑创建第3个Data-Pod替代迁移节点(从仍健康的迁移节点上迁移数据)× ->应该认为原节点完全不可用(相当于节点重搭了)设计方案参考其他数据库产品;;
4.14:推方案不动..自验证copy-shard达到预期效果,但无法解答原理,,自测方式还需模拟实际场景,多线程写入。。
4.15:写bash脚本批量写,开多终端模拟多线程,分片副本达70M+大流量2000point/s写 =》copy-shard恢复出分片副本与健康节点持续写的副本md5值不一致,恢复副本export文件小,猜测丢失数据
4.17:InfluxDB Data节点迁移方案评审:先迁移后逐个恢复分片数据。已验证在分片副本大小70M、写入数据达2000point/s的情况下直接copy-shard会导致增量数据丢失,考虑在copy-shard前先执行truncate-shards截断热分片(集群中所有写入最新数据的分片,截断后关闭写入,变成冷分片),并在所有Data节点上创建该分片的新热分片副本,也就是在迁移节点上恢复了全部原有分片的新热分片副本,最新数据写入这个副本,然后再逐个从健康节点上的冷分片副本copy-shard恢复出分片的历史数据(迁移前分片副本原有的数据&迁移过程中未能写入的数据),该分片数据完全恢复;自测符合预期
4.18-4.21:开发。发现原checkPodRebuildReady接口有时不符合预期,执行influxd-ctl指令(硬写成String在代码中)有时失效(meta no leader..),经常需要手工介入。。
4.22:提测
4.23:InfluxDB开源版可靠性不确定,,社区版,单节点,,开发,值班暂停
官方文档 https://influxdb-v1-docs-cn.cnosdb.com/influxdb/v1.8/introduction/install/
开源influxdb-cluster源码 https://github.com/chengshiwen/influxdb-cluster
Data节点迁移方案
故障矩阵: 架构 => 2 data 3 meta 副本因子为2
DBCLOUD开源DB报警群(实例),DBEngine告警群(机器),致命告警->数据库值班告警处理群,MariaDB/MySQL/MongoDB/PostgreSQL 常见问题,,
数据库开发&值班暂停
4.25-5.8:手动验证全流程+调通API,分阶段做,卡点及时同步到群聊.. 官网找接口文档/厂家提供,postPolicies接口参数调不好,就先手动设好用get查出来构造requestBody..
5.9-5.13:理清自动化接入和改造方案(先看一期代码,考虑接口和表能否复用),主动拉评审会议
5.14-5.16:开发及时理清需求原型和改造点,开发备份域配置管理界面
5.19-5.23:重难点=》作业平台下发备份客户端安装ansible脚本改造,根据传参when指定不同task,实现在target主机安装指定平台的client,expect实现交互式流程
5.26-5.29:NBU备份申请自动化开发,实现BackupNbuService(备份平台NBU涉及代码,构造RestTemplate调API);备份域配置“增删改查”,分页,模糊查询,@Transation处理先删后插/先改后改/先删后删。。延期->0605
6.3:自测=》页面上发起请求获得requestBody/通过postman调用本地起的后端服务,调试=》注释排查法/计算器debug
6.4:发sit,延期->0612;完善todo
6.5:自测,业务验收,ddl&dml(注意StringEncryptor加密的密钥随env变化!!) 发版,存在问题待完善
11.13:产品化客户验收(产品化环境开发、、接入客户环境、、)
制定2025年度重点工作计划。
快速开发InfluxDB服务化需求,持续优化已有功能;深度熟悉开源数据库,确保提供稳定服务。对齐其他数据库产品,了解用户实际需求,多方面考虑设计方案。做好值班任务。
希望提升的1-3项核心能力项,计划如何提升。
1 深入技术栈学习。阅读InfluxDB源码,学习数据库架构设计,K8s应用课程等,掌握高频业务场景的原理和运维技巧。
2 高效合作开发的能力。在全面思考,明确需求后开始开发,遇到卡点快速解决。
面向未来1年的职业规划。
本岗位沉淀
在这个阶段希望提高自己的工程能力,能比较全面地思考设计方案,快速开发和交付需求;还应该具备产品侧思考的能力,对一个系统有深入的认知,能够独当一面,做到专精一个领域。
工作成果
1.InfluxDB服务化体系构建
完成父子实例模式改造,新增InfluxDBMeta规格体系,实现节点级独立变配能力,为后续节点重启、迁移奠定基础;
针对Data节点迁移提出 “热分片截断-冷副本恢复”双阶段法,通过多线程大流量写入压力验证(2000 points/s),解决开源工具增量数据丢失问题;
参与数据库运维工作。
2.NBU备份自动化开发
支持备份平台自动化运维需求,开发基于Ansible的客户端安装脚本,整合NBU API,实现备份申请自动化;
开发备份域配置管理界面(增删改查+JSON字段模糊查询)
能力提升
在InfluxDB服务化需求开发中锻炼了“场景抽象-方案验证”的能力,从寻找开源社区方案到定制化能力开发(如备份集恢复、节点迁移及数据一致性保障),梳理故障矩阵(如单Data宕机、多Meta宕机的应对策略);在NBU备份自动化需求开发中能够快速上手Ansible脚本,复用已有能力,与用户及时沟通并完成开发。
存在不足
数据库开发方面需要积累技术深度,全面考虑方案并推动评审;自动化运维需求开发可以积累解决方案,缩短交付周期。
1 | ## 输入 |
6.27:页面流程理解+看“申请”自动化代码->考虑改造点,找api,输出文档
6.30-7.4:需求对齐,减少开发量的机会,,对于依赖项的变更(healthCheck->ResourcePool-VirtualServer)采用“蓝绿发布”=》先增后删
7.5-7.9:开发完成
7.10-7.11:自测,前端发起一次请求F12取payload / 后端接口处打印入参 + 按需修改 =》构造入参,走通流程,只需关注新加的代码(无关逻辑如校验/审批代码可以先注释掉。。)
7.14:变更成功后回滚。。手动修改+提sql同步配置;思考=》是不是可以直接另提一次变更,或者另外提供回滚接口,,总之此时回滚和前一次变更已经没有关联
7.17:上线。修复 1 管理员节点自动带出尽可能多参数 2 支持定时执行 3 思考:checkChangeSuccess()方法期望同步response,但方法里调API返回fail会隔10s重复十次,就是一直fail的话接口会隔100s才返回数据,假如加了一个定时任务扫描出待变更工单列表,用for循环执行change()并且各调用了checkChangeSuccess(),会发生什么,for循环卡住?”springboot项目,写了一个变更c…”点击查看元宝的回答
https://yuanbao.tencent.com/bot/app/share/chat/qqYiHTHYRWDv
7.29:支持定时执行,注意避免同一个工单被多次扫除(未完成变更后状态->EXECUTED),注意调度任务下发到本地节点,可能由于代码版本不同造成“灵异事件”
10.16:支持变更页面上的所有参数
10.30:支持回收自动化
11.13:优化提交工单时校验逻辑,避免重复补工单(按需增加存表字段&管理端加编辑后门)
解析值。。序列反序列parse,,JSONNode,,
1 | log.error("查询VirtualServer信息异常:"+e.getMessage(), e); |
todo
“一个Java系统开发完了,是怎么跑起来…” https://yb.tencent.com/s/jj0KGxxEGgzU
“IDEA调试、线上运行,Maven、SpringCloud…” https://yb.tencent.com/s/GB2sYz5WPHbB
集成,部署 “所谓的微服务实际上是怎么部署的呢…” https://yuanbao.tencent.com/bot/app/share/chat/gt96bRkSxuos
K8S&微服务部署方案 “k8s和springcloud是如何关联…” https://yuanbao.tencent.com/bot/app/share/chat/H2FtlSdK24y1
feature/v1.1.0发版完成后,拉出最多下两个版本的开发分支,如 bugfix/v1.1.0和 feature/v1.2.0,发版完成后合入线上分支和下一个版本分支。db文件上传git。nohup /usr/bin/java ${C_CMDB_XXL_JOB_EXECUTOR_ONEAGENT_OPTS} -Xms8g -Xmx8g -jar -Dspring.config.location=xx/application.yml -Djasypt.encryptor.password=xx xx.jar > xx.log 2>&1 &运维人员 -> 办公电脑 -> 访问入口 -> 堡垒机(安全审计核心) / 跳板机(简易通道) -> 内网 -> 物理机 / Linux后台(应用载体)
Linux基本命令:
netstat ; top; awk ; dstat; iostat; lsof; free, df;uptime;dmesg ;dig ; nslookup
vim/vi的基本快捷命令(gg, shift + g, :n ; dd, :%d ; yy, p ,u等)
终端的一些快捷命令(ctrl + a; ctrl + e)
1 | # 确认分区使用率 |
/etc/logrotate.d/zookeeper 中设置 daily, rotate 30, compress/apps 比 / 还大?1 | df -h |
1 | # 1. 查找Java应用PID |
1 | # 1:执行在线清空(命令通过文件名找到inode-A并清空数据块,Java进程仍拿着FD=10向原inode-A写日志) |
1 | # 2(错误):直接删除活跃日志文件,目录中文件消失,但Java的句柄FD10仍保留,仍持续写数据到inode-A |
cp + cat /dev/null >1 | cp 原文件 → 备份文件(inode-B) # 复制数据快照 |
cp 期间磁盘空间短暂翻倍(100GB 文件会占用 200GB),耗时较长(100GB ≈ 8 分钟),期间磁盘 IO 高;cp 完成到 cat /dev/null > 之间极短窗口内的日志会丢失(毫秒级,可接受)mv + touch + kill -HUP1 | mv 原文件 → 备份文件 # 瞬间重命名,inode-A 变成备份文件 |
mv 瞬间完成,不占额外磁盘空间,无翻倍风险, 适合超大日志文件场景kill -HUP 到 Logback 真正重新 open 之间有极短窗口,新日志仍写入备份文件(inode-A)1 | 业务代码 |
1 | ll /apps/logs/mongodb/archive/ |
Got signal: 6 (Aborted)(而非被外部 kill - Got signal: 15 (Terminated)):1 | grep "Got signal" /apps/logs/mongodb/archive/mongod30000.log.20XX-XX-XXT17-00-0X |
1 | # 替换为实际告警时间,格式:T小时:分 |
COLLSCAN(全表扫描)、耗时超过 1000ms 的查询、docsExamined 数量级是否异常大docsExamined 最大、耗时最长的那条,提取完整 filter:1 | grep "COLLSCAN" /tmp/crash_window.log | grep -oP '"find": "\K[^"]+' | sort | uniq -c | sort -rn |
1 | filter: { field1: "xxx", field2: "yyy" } ← 这是需要建索引的字段 |
1 | db.hello() |
hosts 列表里,通常是仲裁节点(Arbiter),不存数据,无需关注。1 | db.目标表名.createIndex( |
ip_1_source_1 生效,在 Compass Explain Plan 标签,填入原始 filter: { “ip”: “172.23.135.194”, “source”: “操作系统-其他IP-采集” },Explain 确认 COLLSCAN → IXSCAN,docsExamined: 213667 → 0,耗时 5097ms → 0ms服务:ops-data-access(对外接口)PRD | 端口:7119
关联:`ops-synapplication(实际入库)、MongoDB、Redis
1 | 最大繁忙线程数 |
1 | // MongoDB 审计表,找大批量写入请求 |
事故时间:2026-06-23 02:30 ~ 04:50
影响服务:data-center(CMDB 数据中心服务)
事故等级:P1(服务中断)
cat /dev/null > 清空大文件时暂时占用系统内存,把热数据挤到 Swap 里,导致内存数据混乱分布且无法自动恢复,最终引发 Swap 抖动和服务 OOM。cat /dev/null > data-center-1.0.log(50GB 文件)1 | `si`(Swap In)持续 1000~2000 KB/s:系统在拼命从 Swap 读取被访问的数据 |
1 | Java 访问对象 A(在 Swap)→ Swap In |
1 | ## **触发链** |
1 | # **日志证据** |
swapoff -a && swapon -a(强制清空 Swap,8GB 数据回到内存)cat /dev/null > data-center-1.0.log 清空 50GB 日志文件。truncate -s 0 data-center-1.0.log1 | **触发机制**: |
1 | 物理内存 13.65GB(91% 使用率): |
cat /dev/null > 执行瞬间,内核处理 50GB 文件截断,Page Cache 临时占用 8GB。物理内存不足(13.65GB + 8GB = 21.65GB > 15GB),内核 LRU 算法在需要腾出 8GB 时,把刚用过几分钟的 Java/ilogtail 数据也当”冷数据”换出——**这是”误判”**:正常只需换出 1.1GB 冷数据,这次却换出了包含 4GB 活跃对象的 7GB 数据,Swap 从 1.1GB 暴涨到 8GB。1 | 异常状态(02:32 之后): |
| 状态 | 内存使用 | Swap 使用 | Swap 内容 | 系统稳定性 |
|---|---|---|---|---|
| 正常 | 13.65GB(活跃数据) | 1.1GB(14%) | 全是冷数据 | ✅ 稳定,Swap 几乎不被访问 |
| 异常 | 波动 | 8GB(100%) | 4GB 热数据 + 4GB 冷数据 | ❌ Swap 抖动,永久震荡 |
1 | cat /dev/null > 50GB 文件 → Page Cache 临时占用 8GB |
1 | uptime |
1 | free -h |
1 | vmstat 1 5 |
1 | top |
1 | # 统计有多少进程在用 Swap |
swapoff 需要将 Swap 里的 8GB 数据全部读回内存,但可用内存只有 1.8GB,物理上不够。1 | sudo systemctl stop logagent |
1 | sudo swapoff -a && sudo swapon -a |
1 | sudo systemctl start logagent |
1 | Load: 0.40 |
| 状态 | Swap 使用率 | Load | vmstat si/so | 是否正常 |
|---|---|---|---|---|
| 健康依赖 | 5~15% | < 2 | si=0, so=0 | ✅ 正常(冷数据在 Swap) |
| 危险边缘 | 80~99% | 3~6 | si>100 KB/s | ⚠️ 警戒(热数据开始被换出) |
| Swap 抖动 | 100% | >10 | si>1000, so>1000 | 🔴 故障(热数据混杂,无法恢复) |
0 2 * * * sh /apps/devops/data-center/data-center-log-backup.shcheckPort 方法使用了 7+ 个模块共享的线程池 queryCmdbValidIpExecutor(核心线程数 15)。高峰期其他模块的长耗时任务占满了全部 15 个核心线程,checkPort 的任务只能排队等待,而上层 validatePorts 调用的是 Future.join()(无超时阻塞),导致 API 处理线程永久 pending,直到客户端超时。1 | API 请求 |
1 | @Bean |
mops-platform-backend 服务的 Tomcat 线程池指标(活跃线程数、连接数、请求数等),导致线上问题缺乏可观测性。application.yml 主配置中添加一行:1 | server: |
1 | 生效链路 → |
mbeanregistry.enabled=true 覆盖默认值(显式覆盖默认行为)@EnableAutoConfiguration 扫描 classpath,检测到 tomcat-embed-core 存在,自动创建嵌入式 Tomcat Bean,无需任何 XML 配置。这是”约定”的底层实现机制。queryUserResource 接口偶发 500,错误信息 “ES查询失败”httpcomponents JAR 包版本冲突。elasticsearch-rest-high-level-client 7.17.23 需要 httpcore-nio 4.4.14+,但 Spring Boot 1.5.10 将其降级到 4.4.6。ES 服务端今天 10:22 主动断开连接时,客户端处理断连逻辑触发了缺失的构造方法,导致 I/O reactor 线程崩溃且无法自愈,此后所有 ES 请求全部失败。RestHighLevelClient 有连接池和自动重连机制,ES 服务端断连后客户端会自动重建连接,不需要重启。但本次由于版本冲突,reactor 在处理断连的过程中自己崩溃了——不是断连本身导致连不上,而是处理断连时抛出 NoSuchMethodError 导致整个客户端实例废掉。RUNNING → STOPPED),没有自愈路径,只能通过重启服务重新创建 RestHighLevelClient 实例来恢复。修复版本冲突后,断连会走正常处理流程,不再触发崩溃。INFO.0.log 里搜查询 es接口的错误日志 Error executing search request 没有结果,卡在这里。ERROR 级别所有日志,反而一次性暴露了两个现象——大量 I/O reactor status: STOPPED 和少量 callPaasError,并且从时间戳上看出 STOPPED 在前、callPaasError 在后,有明确的因果关系。grep -n 定位 STOPPED 第一次出现的行号,再用 sed -n 取该行前后的日志,找到崩溃的直接异常 NoSuchMethodError,再往前一屏找到触发原因 ConnectionClosedException: Connection closed unexpectedly。NoSuchMethodError 是版本冲突的典型特征。结合 pom.xml 中 elasticsearch 7.17.23 + Spring Boot 1.5.10 的组合,直接锁定冲突的 JAR 包和版本差异。1 | 10:22:00 ES 服务端主动断开连接 |
LIKE '%值%',无法利用 B-Tree 索引IN 列表(可达数千条),在与 LIKE 并存时优化器会放弃索引改走全表扫1 | POST /backup/getExecRecord |
1 | KEY idx_system_name (system_name) -- 仅无 LIKE 时有效 |
| 场景矩阵 | isHomePage? | 有 LIKE? | 有 IN? | 是否慢? | 原因 | EXPLAIN |
|---|---|---|---|---|---|---|
| 用户端默认进入,无过滤 | true | 否 | 是(权限列表) | 否 | idx_system_name 生效 |
type=ref key=idx_system_name rows=少量 |
| 用户端 + LIKE + 权限 IN | true | 是 | 是(大量) | 是 | LIKE 导致 IN 索引被放弃 | id=1 t ALL possible_keys=idx_system_name key=NULL rows=1,868,591 Using where id=1 id=2 MATERIALIZED id=3 DERIVED No tables used |
| 管理端,仅 LIKE,无 IN | false | 是 | 否 | 最慢 | 无任何索引入口,全表扫 | type=ALL key=NULL rows=3,405,177 Extra=Using where |
| 管理端,LIKE + 少量 IN | false | 是 | 是(少量) | 有风险 | IN 列表很短时 idx_system_name 可能生效,但加了 %LIKE% 后优化器不稳定,数据量大时仍有慢查询风险 | ~ |
%LIKE%会使优化器放弃 B-Tree 索引。1 | -- **关键 EXPLAIN 对比:** |
1 | // 改前 |
1 | ALTER TABLE backup_exec_record ADD INDEX idx_backup_type (backup_type); |
idx_backup_type 将候选集缩小到该类型的子集,后续 LIKE 在小集合上过滤,覆盖绝大多数查询场景。1 | .and(StrUtil.isNotEmpty(condition.getIpAddress()), w -> { |
1 | ALTER TABLE backup_exec_record ADD INDEX idx_ip_address (ip_address); |
10.25.)走索引范围扫描,避免全表扫。% 即可利用索引。 1 | // 改前 |
1 | T+0 定时任务每 5 分钟触发一次采集任务下发 |
1 | jstat → Old 区 99.97%,Full GC 无法释放内存 |
1 | // 锁住整个 Service 实例,所有线程全局串行 |
analysisAutoData() 对每条采集记录循环调用一次,在锁持有期间产生大量短生命周期大对象。 1 | 证据链: |
1 | Full GC STW(每次 600ms)恶性死循环 |
1 | 故障时:-Xms512m -Xmx1g |
1 | // 每条 Kafka 消息创建一个新线程,无上限 |
operKafkaData() 就退出,对象可以被 GC 回收。Kafka Coordinator Dead 后反复重连(而非彻底退出消费组),导致新消息持续涌入,新线程持续创建,内存压力持续增大。1 | // 现状:全局锁,锁内执行数十秒重 IO |
1 | // 现状:无上限裸线程 |
CallerRunsPolicy 的作用:线程池满时由 Kafka 消费线程自己执行任务,消费速度自动降低,形成背压,避免无限堆积。1 | # 现状:自动提交,重启会丢失已消费未入库的消息 |
1 | -Xms4g -Xmx4g # 堆大小,建议取可用内存 40~50% |
1 | 1. 登录宿主机,发现 7001 端口由 Docker 容器监听 |
1 | management: |
1 | sudo docker restart 5f6b2e982c53 |
netstat 看到 docker-proxy 说明是容器端口映射,docker ps | grep 端口 找到对应容器include: "*" 会暴露 heapdump(含密码/token)、env(含明文配置)等高危端点,生产环境应只保留 health/infodocker inspect 看 Mounts,bind mount 类型直接改宿主机文件重启生效,无需重建镜像8.1:梳理变更场景,4种记录+2种平台,拆解为每种记录只有增删改三种操作,一步步实现即可
8.2-8.10:大假,昆明-大理-贵阳-深圳
8.11-8.15:收集+验证现状,还需拉会议评审
8.17:后续每天定 每日计划…
0818:DNS变更,确定所有api/script(√),方案评审(×)
0819:DNS变更主流程(80%)
0820:DNS变更主流程(90%)
0821:管理端加失败工单入库按钮,当日上线
0822-0824:DNS变更开发
0825:DNS变更自测(√),CMDB安全组件安装流程确定(×)
0826:DNS变更sit(√),CMDB安全组件安装(×)
0827:DNS变更全流程报错机制完善,1.流程节点失败就报错 2.ticket.setExecutionLog(+=新日志) 那么可以全程操作溯源、、成功就直接加,失败throwE在catch里加e.getMessage()
0828:涉及定时任务调度/异步的要考虑UserContext空指针;上线
0908:一键回退主流程开发
0916:一键回退上线
1016:全面支持mx+txt申请变更回收,通过workspace让AI“模仿”cname自动化来实现
1030:支持智能解析,todo->cmdb字段回写+移动审批带出
11.18:产品化需求->Windows DNS自动化下发,适配进常规DNS下发流程(midea生产和产品化环境通过前端开放不同入口,实现执行不同部分代码,下发不同platform的DNS配置)
1202:变更一键回退优化(直接挂回原pool),支持申请回退(即回收掉)
后续 → 交接给外包
4.9:不是一股脑交给外包,而是把握、控制好需求、功能后交给外包实现
6.30:变更/回收前同步“元数据”,用于变更/回收脚本下发和一键回退,认为平台值不可信;至此DNS场景基本覆盖完善
二阶段提交以保证两份日志保持逻辑一致)-> 两份日志都成功写入磁盘后,被修改的数据页(脏页)并不会立即写入磁盘,而是由 MySQL 在“后台”选择一个合适的时机异步刷盘。 刚刚好找出这张照片,刚好这一天的头发服帖,刚好朋友拍出了不错的构图,脸上也满是生气,好像有勇气冲到一个新的level
但最近我都在跑医院,想着每个周末只是在修复自己的身体和精神,到了工作日又要回去摧残自己..这有什么意义吗
为了回归到这张照片,想了半天得出一个结论是,不断地修复自己到一个刚刚好的状态就是生活的意义,吗
有点虚无,说了但像什么也没说,什么又是一个刚刚好的状态呢
也许是我刚好能够面对相机,刚好拍下了这张照片
也许人置身生活的洪流,只能不断修复自己
也许可以找到互相修复的人
刚刚好找出这张照片,刚好这一天的头发服帖,刚好朋友拍出了不错的构图,脸上也满是生气,好像有勇气冲到一个新的level
但最近我都在跑医院,想着每个周末只是在修复自己的身体和精神,到了工作日又要回去摧残自己..这有什么意义吗
为了回归到这张照片,想了半天得出一个结论是,不断地修复自己到一个刚刚好的状态就是生活的意义,吗
有点虚无,说了但像什么也没说,什么又是一个刚刚好的状态呢
也许是我刚好能够面对相机,刚好拍下了这张照片
也许人置身生活的洪流,只能不断修复自己
也许可以找到互相修复的人
接手CMDB,,从做需求->做系统 https://yuanbao.tencent.com/bot/app/share/chat/920NVAbsqwtm
最大化CMDB项目的学习价值,, https://yuanbao.tencent.com/bot/app/share/chat/SzQrsGlsuz88
| 简历模块 | 平庸写法 | 高价值写法(量化+技术关键词) |
|---|---|---|
| 项目经验 | 参与CMDB需求开发 | 主导CMDB数据模型重构,设计弹性CI架构,支持200+动态属性扩展,模型变更效率提升40% |
| 技术亮点 | 使用Spring Cloud开发API | 基于Quartz+Netty开发高并发自动发现引擎,单节点支持5000+设备/秒采集 |
| 业务价值 | 提升系统稳定性 | 通过拓扑影响分析模块,故障定位时效从30min缩短至5min,年止损运维成本200万+ |
💡 简历筛选口诀:“技术深度×业务影响”双突出——避免写“增删改查”,聚焦架构设计、性能优化、跨系统集成。
1 | ⬇️ 内部 主机部署 |
1 | ⬇️ 私有化 k8s容器部署 |

ChatClient ←→ PromptTemplate ←→ ChatResponse1 | // 1. LLM解析 → 需要调用queryHosts工具,参数: osType="Linux", minMemory=8 |
1 | // 1. LLM解析 → 需要调用queryHosts工具,参数: osType="Linux", minMemory=8 |
1 | // 1. RAG检索 → 相关性能优化文档 |
可体验的竞品:
竞品核心功能提取:
• 自然语言转查询:”内存大于8G的服务器” → MongoDB查询
• 结果格式化:表格、图表、自然语言总结
• 错误处理:查询无结果时的智能建议
(Python demo using LangGraph) https://github.com/leo710aka/CMDB-Chat/blob/main/cmdb_chat.py
nl2sql开源项目:https://java2ai.com/agents/dataagent/quick-start/
1.16-1.22:MOPS大洋产品化功能验证。。差异本地起多服务验证,在sit环境验证poc分支代码,要注意配置差异
1.23:容器化服务验证 → image上传-bundle打包load到私有仓-pod重启,分步验证,相信自己能解决问题。
1.26:不管在什么环境,排查问题看日志(项目配置里查,不懂就问,超过1h解决不了就抛出)
2.10:大洋uat演示
2.26:私有化代码迭代规范搞清楚(主干分支,迭代分支,输出分支)
3.20:关键是理解用什么分支,出什么包(什么仓库什么标签的image),部署到什么环境
5.11:NBU整机备份验收
5.15:?windowsDNS改造WinRM下发(解决ssh登录执行ps指令二跳认证问题)
pom.xml 文件。它定义了项目坐标、依赖的第三方库(如Spring Boot)、插件等。一个基本的打包命令是 mvn clean package,执行后会在 target/ 目录生成可运行的JAR包。java -jar 直接运行,是Spring Boot的默认方式。Thin JAR 则只包含您自己的代码,运行时需要显式指定依赖库的路径(Classpath)。java -jar your-application.jar 即可启动应用。您可以通过 --server.port=8081 这样的参数覆盖配置文件中的设置。ps -ef | grep java 或 jps -l 命令,可以查看当前系统中所有Java进程的PID(进程ID)和主类名。kill -9 <PID> 可以强制终止一个Java进程。更优雅的方式是在应用中通过Actuator端点实现kill -15 <PID>(发送SIGTERM信号),允许程序完成当前任务后再退出。nohup java -jar your-app.jar > /path/to/app.log 2>&1 & 命令实现后台运行并将日志输出到文件。ThreadPoolExecutor)来管理和复用线程,减少资源消耗。在Spring Boot中,利用 @Async 注解可以轻松实现异步方法调用。使用 top -H -p <PID> 命令可以查看某个Java进程内各个线程的CPU和内存占用情况,帮助识别资源消耗大户。curl -O https://arthas.aliyun.com/arthas-boot.jar 下载,然后用 java -jar arthas-boot.jar 启动并选择要诊断的Java进程。dashboard:实时仪表盘,总览系统状态。thread:查看所有线程堆栈,找出阻塞或CPU占用高的线程。watch com.example.YourClass yourMethod "{params, returnObj}" -x 3:动态观察方法调用的入参和返回trace com.example.YourClass yourMethod:追踪方法内部调用路径及每个环节的耗时。java -version 和 mvn -v 验证。Spring Web 依赖)。在项目根目录执行 mvn clean package,观察 target/ 目录下生成的 .jar 文件。java -jar target/your-demo-app.jar。jps -l 找到该进程的PID,用 ps -ef | grep java 查看详细信息。http://localhost:8080 验证应用。kill -15 <PID> 优雅停止应用。thread 命令找到繁忙线程,再用 stack 命令查看该线程的完整堆栈,定位问题代码。^^
// todo:本地?远程linux?实验
确定自己的项目边界,,杂事给外包??运营工作形成sop
确定主线、支线任务,,每天能回想起自己做了什么吗。。
找到专精??晋升,数据库,,
ai coding
1.5:CMDB问数项目启动
1.7:datamax问数体验,开启多轮问答方案调研(确定表-确定字段-确定sql..)
1.9:DataAgent项目体验,SpringAiAlibaba,Apache2.0
1.11:DataAgent配置llm+embedding,初始化数据源embedding到本地vectorStore,,Graph多轮问数
1.12:DataAgent验证业务提供的场景
1.15:多轮验证报告=》可能提高准确性,但需要维护多个节点
2.26-3.6:基于DataAgent二开 → 看详细功能实现,多轮逻辑图,节点路由关系,每个节点做了什么,,
3.7-:定制化改造,结合内部场景验证,完善缺陷。。
laster:CMDB交接,,问数项目sit验证,“后面能不能发都不知道了”
1 | # 编写 Dockerfile(极简模板,可直接复用): |
1 | # 用命令创建命名空间(示例:命名空间名为 demo) |
1 | apiVersion: apps/v1 |
1 | apiVersion: v1 |
1 | apiVersion: networking.k8s.io/v1 |
【结论】Java 服务在 K8s 跑起来后,外部访问入口本质是:Ingress 关联的 IP + Java API 路径(通常不需要额外加 Port)
配置的 Ingress 规则,本质是告诉 Ingress Controller:“当收到某个 IP / 域名 + 路径的请求时,转发到对应的 Service → Pod → Java 服务”
无需关心 Service IP 和 Pod IP,Ingress 已经帮你做好了所有转发。
| 组件 | 核心职责 | 是否会变 |
|---|---|---|
| Deployment | 管理 Pod 生命周期(升级、自愈、副本数) | 配置不变则不变 |
| Pod | 运行 Java 容器,集群内部私网 IP | 更新镜像/重建时,IP 必变 |
| Service | 固定内部入口,负载均衡到 Pod | 不删除则 IP 不变 |
| Ingress 规则 | 配置外部域名→Service 的路由 | 不修改则不变 |
| Ingress Controller | 执行转发,集群全局组件 | 运维维护,通常不变 |
外部用户访问 → 域名 DNS 解析 → Ingress Controller(ingress-nginx 命名空间)
→ 匹配 Ingress 规则(demo 命名空间) → 转发到 Service(demo 命名空间,固定 IP)
→ Service 负载均衡(DNAT) → 转发到某个 Pod(demo 命名空间,私网 IP)
→ Pod 内 Java 容器处理请求 → 返回数据
微服务架构中,有到网关微服务,负责选具体服务的节点
1 | 🌍 用户浏览器 |
一句话极简链路:浏览器 → DNS → 节点IP:80 → Ingress Controller → 网关Service → 网关Pod → 业务Service → 业务Pod
K8s环境服务访问,相互调用
轻量化??
todo:https://time.geekbang.org/column/intro/100015201?tab=catalog
| 阈值 | 判断 |
|---|---|
| < 100ms | 正常 |
| 100ms ~ 1s | 关注,高频接口需优化 |
| > 1s | 慢 SQL,需处理 |
| > 3s | 严重,必须处理 |
select_type——子查询的执行策略| 值 | 含义 | 好坏 |
|---|---|---|
| PRIMARY | 主查询 | — |
| MATERIALIZED | 子查询物化,只执行一次 | ✅ 好 |
| DEPENDENT SUBQUERY | 相关子查询,主表每行执行一次 | ❌ 危险 |
| SUBQUERY | 独立子查询,执行一次 | ✅ 好 |
DEPENDENT SUBQUERY 是慢 SQL 的高危信号,主表 N 行 × 子查询 M 行 = N×M 代价
type——单表访问方式(性能从好到坏)| 值 | 含义 | 好坏 |
|---|---|---|
| ref | 索引等值查找 | ✅ |
| range | 索引范围扫描 | ✅ |
| index | 全索引扫描 | ⚠️ |
| ALL | 全表扫描 | ❌ |
const > eq_ref > ref > range > index > ALL
key——实际用的索引(NULL = 没用索引,结合 type=ALL 是最差情况;有值但 type 仍是 index/ALL,说明索引未能有效过滤)rows——预估扫描行数(越大越慢;DEPENDENT SUBQUERY 的 rows 要 × 主表 rows,是乘法关系)Extra——额外信息| 值 | 含义 |
|---|---|
| Using where | 引擎拿到数据后 Server 层再过滤,正常 |
| Using index | 覆盖索引,无需回表,✅ 好 |
| Using index condition | 索引条件下推(ICP),减少回表,✅ 好 |
| Using filesort | 需要额外排序,⚠️ 关注 |
| Using temporary | 用了临时表,⚠️ 关注 |
1 | 按以下顺序逐一排查: |
优先级从高到低:
| 策略 | 适用场景 | 收益 |
|---|---|---|
| 消除 DEPENDENT SUBQUERY | 子查询被反复执行 | 从 O(N×M) → O(N+M),数量级提升 |
| 加索引 | type=ALL 且 WHERE 列无索引 | 从全表扫 → 索引查找,数量级提升 |
| 去掉子查询中多余的 JOIN | JOIN 列与 SELECT 列相同导致 DEPENDENT | 可能让优化器改为 MATERIALIZED |
| 覆盖索引 | 频繁回表 | 消除回表,中等收益 |
| 改写为 LEFT JOIN IS NULL | NOT IN 子查询 | 视情况,需验证 |
⚠️ LEFT JOIN 改写不一定更快:如果主表没有先缩小范围就做全量 JOIN,反而会更慢(本次实验验证过)
改完后重新 EXPLAIN,对比关键列变化
重点确认:
1 DEPENDENT SUBQUERY 是否消失或 rows 大幅减少
2 type=ALL 是否变为 ref(索引等值查找)/ range(索引范围扫描)
3 key=NULL 是否命中了索引
再实际执行计时,和改前对比
// todo: 多次实践
email、file、baidu-drive、webdav… 核心:定义统一的输入输出格式 ,模型只跟 Skill 说话,不碰具体系统qq-email-adapter - 163-email-adapter - baidu-drive-adapteremail , 生成统一参数:1 | { "skill": "email", "action": "list", "params": { "limit": 3 } } |
email.list(limit=3), 看你配置:你的邮箱是 xxx@qq.com → 自动路由到 QQ 邮箱适配器, 把参数补全:1 | { "host": "imap.qq.com", "port": 993, "user": "xxx@qq.com", "pass": "授权码", "limit": 3 } |
1 | [ |
1 | 用户自然语言指令 |
FileRead/FileEdit/Write(多文件批量改)BashTool(编译、测试、打包、Docker)GitStatus/Commit/Push/PRRipgrep(代码库全局搜索)rm/docker),安全可控。[近年AI应用技术串讲与优质文档分享|Agent、Skill、OpenClaw、Harness……]https://oigi8odzc5w.feishu.cn/wiki/WBMfwiNkfi6uNFkRtXdcavDzn0e
todo 设计、开发一个 【监控】 高并发系统,学习多线程、mysql锁、、
1 | // C:\Users\caife\.claude.json → 配置免登录 |
1 | # 1. 正确的API中转地址 |
1 | # 进入交互式对话,然后直接打字提问 |
CC Switch 可以统一为本地的各CLI配置各模型厂商,启用后 /model 可以看到当前在用模型,无需配置环境变量(下载 xx.windows.msi → https://github.com/farion1231/cc-switch/releases)Vibe Coding 新手起步:必做清单Token 是 AI 处理文本的最小单位。Context Engineer)1 | 长期记忆(磁盘) --> 会话开始时加载 --> 进入上下文窗口(短期记忆) |
1 | # Memory Index |
1 | ● Skill 已创建完成。结构如下: |
1 | > /update-config |
1 | ● User answered Claude's questions: |
MOPS & CMDB & Ansible(运维平台,数据底座 + 运维作业)
MOPS:通过工单触发一个申请/变更/回收流程,通过生成的记录映射到的实际平台上的策略,用API/script做自动化,运维数据落到 CMDB。。流程 可靠(可追溯、可回滚),运维数据全流程闭环,,
作业平台:免密ssh下发(执行机root存私钥,目标机mdauto存公钥),高并发,高可用??三个节点,100个任务,怎么调度,怎么等待??
CMDB:运维事实库,本质就是如何把数据写入,如何供外部使用,日常/私有化迭代(只做热点运维工作,日常用户答疑,没有深耕功能和组件)
CMDB Copilot:基于CMDB数据源的nl2sql问数服务。。搞容器化 → 不用框架,只用通用模型+上下文工程+skills(提示词工程) 怎么实现??
嘉为蓝鲸,Azure 智能运维
价值,用户,钱
ToB:流程和稳定(业务复杂,数据准确,并发要求低),超出客户期待
中立云:目标客户→对成本重视的企业の数量级>>对成本不重视的,对公有云降维打击,占领云计算的农村
迭代:私有化主干分支 feature/product_output 或 poc(区别于内部main分支,两个分别维护,短期方便但长期废人力),私有化迭代分支 feature/priv1.x.0(初期从主干拉出,迭代开发私有化功能),私有化Release版本(中期从主干拉出,私有feature测完后合入,出正式的私有化镜像包)
单一master分支改造:大洋代码合回内部主分支,后续迭代考虑如何一套代码跑多个环境。。客户适应系统,而不是系统适配客户??
MOPS:懂关键能力实现&组件原理,,慢sql治理??线上问题,服务、DB、中间件不可用??
运维作业:流量大怎么做(分批,下班时间),失败怎么做(重试?保证数据一致性;考虑如果失败的堆积到一起重试流量太大。。)
稳定性建设:四大类检查
故障复盘
运维产品
数据库运维
AI Coding:形成开发规范 1)理解项目(形成doc,skill??团队经验)2)配置代码格式等 3)AI根据需求描述生成计划,头脑风暴 4)分步开发(太长思考中断)
AI工程vs传统工程 —「道法术」中的变与不变 https://mp.weixin.qq.com/s/Foiid7aYvTD0-ejBSGhM7A
AI 驱动的智能异常处置:从异常发现到根因定位 https://mp.weixin.qq.com/s/VHqYQ-cnburG8ydI94F_DA
凌晨 3 点故障告警,我让 AI 在 10 分钟内找到了根因 https://mp.weixin.qq.com/s/Ru_tYyofOqnKitzAU7Bu7g
事情多,都紧急,人脑过载,效率低,,
我总是在等一个时机
等有时间再看项目疑难问题
等有时间再学容器化、K8S、调优
stn:没有舒适区
老板好,临近年中,我梳理了下近半年的工作重点:期间完成了 MOPS 所负责业务的持续优化,Opspace 私有化部署,CMDB 问数项目初步上线,同时也更多承担了团队协作事项,日常也有在扩充自身技术栈。
不过对照年初沟通时,您对我的发展期许来看,目前我实际负责的工作内容还是有一定出入。所以想借年中这个节点,跟您再对齐一下您对我的个人成长期望,以及我后续的工作重心安排。另外年初我主动提过想要争取晋升,也想听听您对我现阶段工作的整体评价,以及我自身还需要做出哪些调整改进。
老板下午好,今天是想跟您同步一下我近半年的工作产出、个人成长,以及现阶段的一些想法与困惑。
第一,我持续在做运维平台所负责模块的迭代优化,掌握需求对接和交付的全流程,特别是对DNS自动化这一块做了全场景的梳理和优化方案,也把业务经验沉淀了skill。另外主动支持两位外包做负载均衡和DNS相关需求的方案评审。
第二,大洋私有化交付方面。我不仅完成了自己功能的跑通,更是对整体部署交付流程有了更深的理解,能够积极响应用户问题和需求,支持定制开发和优化,目前是这方面的主力。CMDB 产品化日常迭代也是我在负责。
第三,CMDB智能问数项目,从业务知识梳理、问数场景搜集,到多轮问数定制开发和最终的服务上线均全程改进。当然我清楚知晓,在知识库和问题调试上还有要优化的空间,我也很愿意接下来继续投入时间在这上面。
第四,更多的承担了团队日常值班、发版、线上问题处理,sql优化,CMDB日常运营。
这半年我最大的转变,就是从被动接受任务,到主动梳理工作重点,推进项目,及时同步进展。占用团队资源更少了,能够负责的事务更多了,几位前辈也应该能比较明显感受到。
当然我也有一些困惑,您之前一直给我提的独当一面,事实上我更多的是负责了更多更广泛的业务,而不是专精一个方面。而且近几个月都是高强度满负荷的工作,感觉自己被困在了各种迭代优化的细致项上了,私有化交付更是需要频繁和用户沟通,一直被分散精力,缺少深挖技术的场景(?)。这方面希望您给我一些方向上的指点。
年初的时候我主动跟您提过想争取晋升的机会。我自认为近两年已经有了比较大的成长,也能够实际的承担更多工作。解决实际问题,独立开发。我入职时的薪资就是低于行业平均标准的,但是一直积极进取,也真心希望得到公司的认可,希望能把握住晋升机会。这一块想了解您对我的评价?在哪些方面要重点改进?
开发能力肯定ok
架构(服务拆分,中间件选择,高可用,数据库,微服务,服务治理)
代码规范(《重构》,学习优秀开源项目,Spring)
AI使用(主动学,窗口期1-2y,思考用ClaudeCode怎么做CMDB问数)
做AI运维(主动拓展scope,从日常的杂活中抽理出来,看别人的=自己做了)
独当一面(一方面是能够解决热点问题,一方面是能从0到1落地项目)
保持好奇心
嫡系应届生专属深度谈心方案
hr talk
新boss 一对一完整沟通方案
沟通核心目标(最重要)
1)可量化、可落地的工作:2 次、5 个、8 项、10 +,数据支撑足
2)有具体思路和操作,不是“我做了什么”,而是“我解决了什么”
kafka-2.xx/config/.. 文件前置环境变量:
BK=xxx:9092(集群地址,替换成实际集群)、TOPIC=xxx、GROUP=xxx
1 | # 1.查看全量消费组,找到异常Topic绑定的消费组( 原生没有命令可以「根据 Topic 反向查所有消费组」) |
1 | # 2.查看Topic分区信息,确认分区数量、副本状态 |
1 | # 查看消费组全分区堆积LAG、消费位点、绑定消费实例 |
1 | # 1. 实时监听新消息(看当前涌入的异常消息,从头消费不建议,堆积量大会卡) |
1 | # 2. 只读取20条最新消息,快速抽样 |
kafka-topics.sh --bootstrap-server $BK --describe --topic $TOPICkubectl get pods -n 业务ns | grep 服务名,查看是否CrashLoopBackOff;kafka-consumer-groups.sh --bootstrap-server $BK --group $GROUP --topic $TOPIC --reset-offsets --to-latest --execute1 | #1.扩容Topic分区(提升最大并发,分区只能加不能减) |
一、自动化运维平台能力建设
主导 F5 负载均衡、DNS 域名解析、NBU 备份自动化搭建。完善负载均衡变更、回收自动化链路,减少手工运维成本与操作风险;覆盖 DNS 各类域名申请、变更、回收自动化场景,近半年工单数1000+,创新打造一键回退功能,支持临时域名快速回收、变更故障回滚场景,收获业务方认可。
日常承担平台发版、值班、系统调优等团队事务,负责 F5、DNS 模块需求方案评审,协同团队落地负载均衡变更一键回退、DNS 自动采集、续期盘点等功能。后续将承接防火墙模块,负责网络管理模块迭代。
二、OPSpace 产品化交付
全程跟进 OPSpace 在大洋电机从测试到生产环境交付。核心完成 Windows DNS、NBU 备份自动化的客户侧适配搭建,实现顶级域名可配置、NBU 整机备份等定制化能力,协同客户完成上线验收并输出操作指引。响应闭环各类问题10余项;熟练掌握服务打包构建、多环境适配部署等整套交付技能,支撑项目平稳交付。
三、CMDB 平台运营与数据治理
负责 CMDB 数据运营,对接业务方数据写入和查询需求,辅助业务问题排查。承担日常值班工作,并将自助运维经验沉淀为 skills 上架技能广场。负责系统运维,协同排查服务高负载、接口查询缓慢、Kafka 堆积等故障,现阶段保障存量业务稳定,并协助业务迁移至新版 CMDB。
完成 CMDB 智能问数项目落地,参与从内部知识库构建、多轮问数定制化开发调优,到应用服务的搭建上线全流程;以及在大洋电机交付工作中,排查并闭环部署问题 8 项,保障交付进度。
四、InfluxDB 数据库服务化开发
参与 InfluxDB 服务化能力建设,实现实例备份与恢复、父子实例改造、节点重启与变配能力开发,完成 Data 节点迁移调研与前期开发,积累了数据库与容器化开发经验。
自定义线程池
1 | @Bean |
1 | 任务执行流程(必背) |
生产规范:禁止直接使用Executors创建线程池,必须手动new ThreadPoolExecutor,指定有界队列+合理拒绝策略,防止无限任务/线程引发OOM。
参数该怎么合理设置?(业务实战经验)
核心线程数 = CPU核心数 + 1核心线程数 = CPU核心数 * 2 或者 CPU核心数/(1-0.9)ArrayBlockingQueue设置固定容量,根据业务峰值预估,不要用无界队列。CallerRunsPolicy,不丢数据,让调用方限流;DiscardPolicy;AbortPolicy,捕获异常返回业务繁忙。?? 常用使用方式
1 | pool.execute(() -> { |
1 | Future<String> future = pool.submit(() -> { |
1 | CompletableFuture.supplyAsync(() -> { |
Spring Boot 默认线程池
| 类别 | 作用 | 线程数 |
|---|---|---|
| tomcat 线程池 | 处理 HTTP 请求(你的 API 接口就跑在这里) | 核心 10,最大 200 |
| @Async 线程池 | 处理 @Async 注解的异步方法 | SimpleAsyncTaskExecutor(每次新建线程,无复用) |
| @Scheduled 线程池 | 定时任务 | 单线程 |
并发设计 SOP —— 线程池使用规范
portCheckExecutor、cmdbQueryExecutor判断标准:只要两类任务的执行时间量级不同(ms 级 vs 秒级),或 SLA 要求不同,就必须隔离。
1 | // 禁止 |
1 | 提交任务 |
1 | future.cancel(true); |
TimeoutException),但线程池里的任务仍然继续执行,只是结果无人消费。这是 CompletableFuture 与线程池解耦的本质——调用方的取消意图无法传递给线程池。适用:带数据库查询的 Java Web 服务(Spring Boot + Tomcat + 关系型/文档型数据库)
排查顺序总览:① Tomcat 线程 → ② CPU/内存/GC → ③ 外部调用 RT → ④ 数据库连接池 → ⑤ 慢查询 (每步的结论决定下一步的方向
判断:服务自身撑不住,还是在等别人?
| 指标 | 正常 | 危险 |
|---|---|---|
| 最大繁忙线程数 | < max 的 70% | = max(打满过) |
| 当前处理中请求数 | 波动正常 | 持续居高不下 |
| 待处理请求数 | 0 | > 0(在排队) |
根据结果判断:
1 | 处理中线程数高 + CPU 高 → 第②步,计算密集或 GC 问题 |
三个关键参数
| 参数 | 类比标准线程池 | 作用 |
|---|---|---|
min-spare-threads |
corePoolSize | 最小空闲线程数,始终保活,应对突发流量 |
max-connections |
maximumPoolSize | Worker 线程上限 = 最大并发处理请求数 |
accept-count |
队列长度 | 线程满后 TCP 层的等待缓冲,0 = 满了直接拒绝连接 |
1 | RUNNABLE → 等待 OS 调度,可以拿 CPU(计算中) |
1 | Feign 调用 / 等数据库连接 |
CPU 高的常见原因:
| 场景 | 特征 |
|---|---|
| 大对象 JSON 序列化 | RT 高,CPU 持续高,内存同步上涨 |
| 正则/加解密密集计算 | CPU 高,特定接口慢 |
| 线程数过多导致上下文切换 | CPU sys 占比高 |
| Full GC | CPU 出现周期性尖刺,服务周期性卡顿几秒后恢复 |
Full GC导致卡顿的特征:
1 | 内存使用率持续攀升,接近堆上限 |
CPU/内存正常但服务慢(最隐蔽)→ 这种情况监控无告警,唯一证据是 Tomcat 处理中线程数升高:
1 | 线程挂起等待 IO(DB 连接 / Feign 调用 / 分布式锁) |
判断:慢在哪个下游?
查看 APM 中本服务对外的调用耗时,重点对比问题时段 vs 正常时段的 RT 基线:
判断:是连接池耗尽,还是 SQL 本身慢?
| 关键指标 | 含义 | 危险信号 |
|---|---|---|
| active connections | 当前占用的连接数 | 接近 max-pool-size |
| pending threads | 等待获取连接的线程数 | > 0 |
| connection acquire time | 获取连接耗时 | > 0ms(正常应接近 0) |
| connection timeout 次数 | 等连接超时失败数 | > 0 说明已出现获取失败 |
acquire time > 0ms是最早的信号:连接池空闲时获取连接几乎是瞬间的,一旦出现等待,说明连接池在某个时刻已经被耗尽。
| 如何区分 → | 连接池耗尽 | 慢查询 |
|---|---|---|
| acquire time | 飙升 | ≈ 0 |
| 受影响的 SQL | 全部 DB 请求都慢 | 只有特定 SQL 慢 |
| active connections | = max-pool-size | 正常范围 |
| 慢查询日志 | 无(SQL 还没执行就卡住了) | 有记录 |
| 根因 | 连接池设太小 / 有慢 SQL 长时间占用连接 | 缺索引 / 数据量暴增 |
| 指标 | 危险信号 |
|---|---|
| 慢查询数 | 突然增多 |
| 活跃连接数 | 接近 max_connections |
| 锁等待次数 | > 0 |
| 索引命中率 | 突然下降 |
| 根因 | 判断方式 |
|---|---|
| 缺索引 | EXPLAIN 查看执行计划,type=ALL 表示全表扫描 |
| 数据量暴增 | 对比表行数历史趋势 |
| 查询条件不走索引 | 索引字段被函数包裹、隐式类型转换 |
| 锁竞争 | 查锁等待日志,找持锁 session |
| 返回数据量太大 | 分页参数过大、缺 limit |
1 | 根因(任选其一) |
top命令展示的),是整机所有进程的CPU总和,包括内核、MySQL、Kafka、Java应用、Nginx等。top按下大写 P,能看到java进程单独占用的CPU百分比。举例子:4核机器。Java开启8个CPU密集型线程,8个线程竞争4个核,会出现大量上下文切换,整机CPU直接打满。IO‑密集型(等待数据库、网络、Kafka响应):线程大部分时间阻塞休眠,几乎不消耗CPU。
top(定位Java进程PID) → top‑H‑p PID(查看哪些Java线程占用CPU) → jstack(导出线程栈) → 把十六进制TID在线程栈中定位代码 → 定位代码问题;jstat、jmap排查GC情况。1 | top |
1 | # -H 展示线程,-p 指定进程 |
1 | printf "%x\n" 29065 |
1 | jstack 28940 > jstack.txt |
jstat -gc 28940 500 每500毫秒打印一次GC情况,重点观察:YGC、FGC发生频率是否极高;Old区内存快速上涨jmap -dump:format=b,live,file=heap.hprof 28940 导出堆快照,事后使用 MAT 工具分析。第一阶段:判断严重程度(2 分钟内)
1 | # 确认进程 PID |
| O 列 | FGC 增速 | 单次 FGCT | 判断 | 动作 |
|---|---|---|---|---|
| < 80% | 偶发 | < 200ms | 正常 | 观察 |
| 80~95% | 每分钟数次 | 200~500ms | 警惕 | 准备干预 |
| > 99% | 每秒 1~2 次 | > 500ms | 失控 | 立即抓现场 |
第二阶段:抓取现场证据(5 分钟内)
1 | # 先抓线程快照(几乎不影响进程) |
为什么先 jstack 再 jmap:jmap dump 会触发一次 Full GC + STW,可能导致进程短暂无响应,jstack 先拿到不受影响。
第三阶段:分析 jstack(5 分钟)
1 | # 线程总数 / BLOCKED 线程数 |
第四阶段:止血重启
1 | # 复查 GC 趋势 |
第五阶段:事后 heap dump 分析,用 Eclipse MAT 打开 .hprof 文件:
| 步骤 | 操作 | 目的 |
|---|---|---|
| 1 | File → Open Heap Dump | 加载文件 |
| 2 | Leak Suspects Report | 自动分析内存泄漏嫌疑,最快定位 |
| 3 | Dominator Tree | 找占用内存最大的对象树 |
| 4 | Thread Overview | 查看每个线程持有多少内存 |
…
不用框架,只用通用模型+上下文工程+skills(提示词工程)??
理解:ClaudeCode常规来看是一个CodingAgent,是大模型+编程skills+编程cli,如果替换为大模型+问数skills+问数cli → 问数Agent ??
Frank:方法简短、复用,逻辑正确,嵌套不要太深
自我介绍。
面试官您好,我是蔡枫,本科毕业于华南理工大学计算机学院,在美的集团从事Java后端开发的工作。
我主要接触两方面的工作,目前正在做的是自动化运维平台的开发,面向整个集团的用户提供主机、网络管理相关的服务,我们的工作就是把以往通过管理员手动下发的工作实现流程化、自动化,保证可追溯和甚至可逆。另外,还做了半年的数据库服务化开发,建设InfluxDB的“数据库即服务”(DBaaS)能力,基于开源Influxdb Cluster支持了备份恢复、变配、迁移等功能,但是后期随着对开源数据库的可靠性存在顾虑中断了。
为什么要跳槽?为什么tob,为什么2c?中台?
从晋升结果来看,业务产出少可能是得不到认可的原因。
不局限tob/c,我还还年轻,有信心尝试不同的领域。要持续学习,保持好奇。做中台就像一个螺丝钉,不断修修补补,比较无趣(运维场景深度待挖掘)
工作一年以来对Java开发的理解。
整体比较符合预期,就是解决实际问题的根据,利用算法&数据结构,实现具体的需求。目前不可避免的陷入在很小的领域(很具体的功能)编写杂七杂八的业务逻辑,但这是总来有执行者来做的工作,我觉得关键是前期方案设计时保证整体的可靠性和通用性(自动化场景1 2 3,平台1 2 3),做需求时总结出sop,或者直接交给AI来做
AI的使用,AI工作流
AI Coding
我的工作流就是将人类的战略思维(Strategy)与AI的战术执行(Tactics)分离。我负责定义‘做什么(What)’和‘为什么(Why)’,而AI负责‘怎么做(How)’,并通过 Hook 和 Review 机制确保结果的可控与高质量。
如何保证AI Coding代码质量?
AI开发中对SDD的理解
“总而言之,SDD 不仅仅是一个开发流程,它更是一种工程思维的转变。它标志着我们从‘凭感觉编程’(Vibe Coding)进入了‘按规范交付’的工程化时代。对于后端开发者而言,掌握 SDD 意味着我们不再是 AI 生成代码的被动接收者,而是通过定义清晰的‘契约’,主动地、系统性地驾驭 AI,确保交付的软件既正确又符合业务意图。这正是在 AI 时代,后端工程师核心价值的体现。”
AI coding如何节省Token?
核心:少输入、少输出、少交互、精上下文
面试回答:原则 + 6个具体方法 + 总结价值
亮点:体现你会用 AI、懂成本、有工程规范
Agent如何节省Token?
同样的模型,同样的提词,输出结果一定一样吗?
结论先说:默认情况下一定不一样;只有严格锁死全部条件,才能做到每次输出完全相同
Skills?
“简单来说,Agent Skills 就是AI的标准化岗位说明书。它通过 SKILL.md 文件将领域知识、操作步骤和脚本封装起来。最巧妙的是它采用了渐进式披露机制,只在需要时才加载详细内容,既保证了效果又节省了 Token。如果说 Tool 是 AI 的手和脚,那 Skill 就是 AI 的‘肌肉记忆’和‘工作经验’。在2026年,构建高质量的 Skills 库是企业级 AI 应用落地的关键。”
cf:skills提供业务知识,让llm从普通员工→该业务的资深员工,区别于预设好场景提前设计好Prompt模板供模型使用,Skills让LLM能按需自行构造Prompt?!
RAG?落地?
三大原则:强调项目业务价值、标准项目叙事结构、预埋知识点引导面试官提问,主动导向自身准备充分的技术栈。
🗄️🔗 项目一:CMDB 基础配置数据库
CMDB 是美的集团统一 IT 资产配置底座,作为全集团自动化运维体系唯一可信数据源。集团拥有上万台服务器,覆盖复杂制造业运维场景,上层 MOPS 运维平台、备份系统、监控平台全部依赖 CMDB 资产数据;一旦数据失真、服务读写卡顿,所有变更操作、线上故障根因定位都会失去依据,所以保障数据准确与服务稳定是核心目标。
我作为平台管理员,负责业务接入、核心功能运维、线上故障兜底与私有化交付。平台基于 MongoDB 存储资产信息,围绕数据同步、资产采集、快速检索三大核心能力建设:
1.数据订阅能力:为满足下游众多系统增量同步资产数据的需求,我们基于 MongoDB Oplog 实现变更监听,资产表新增、修改、删除事件自动触发回调接口,完成增量数据推送。依托 Oplog 天然的数据变更日志机制,规避轮询查询带来的数据库压力,我也深入研究了 MongoDB 复制集、Oplog 存储与过期清理机制。
2.资产自动采集:以防火墙策略采集链路举例,整体依靠 XXL-Job 调度下发采集任务,任务投递至 Kafka;采集执行服务消费消息,通过 API 调用、Ansible 远程执行、FTP 拉取多种方式获取远端设备配置,采集结果再次投递 Kafka;采集代理消费消息,完成数据清洗后入库 MongoDB。整条链路依赖 Kafka 实现异步解耦,日常处理过大量生产消费速率不匹配导致的消息堆积问题。
3.全文检索能力:借助 mongostash 组件,将 MongoDB 资产数据实时同步至 Elasticsearch,对外提供统一检索接口,解决 MongoDB 复杂模糊查询性能差的痛点,支撑业务方快速检索各类资产。
除功能迭代支撑外,我大量精力投入平台稳定性运维与故障闭环:经常遇到查询接口响应缓慢、视图查询超时问题,多数根源为缺失合适索引,通过优化索引策略持续优化查询性能;针对服务整体读写卡顿,沉淀标准化故障排查 SOP,依次排查容器资源、外部接口耗时、数据库慢查询逐层定位瓶颈;常态化处理 Kafka 消息堆积、Java 应用频繁 FullGC、OOM 内存溢出等线上问题。
同时负责平台私有化容器化交付,独立定位并修复 ZooKeeper 集群启动异常问题:原配置固化集群 IP,容器重建后 IP 变更导致集群失联;我在集群健康状态下执行 reconf,使用域名替换固定 IP,彻底根治该缺陷,保障私有化环境长期稳定运行。
【预埋引导话术,自然穿插】
整套系统混合使用 MongoDB、ES、Kafka,在实践中能明显感受到文档数据库在强事务场景存在短板,这段时间我也系统深入学习 MySQL InnoDB 索引、事务、锁相关理论,对比两类数据库适用场景差异。
🛠️ 项目二:自动化运维平台开发与产品化
🤖 项目三:CMDB-Agent自然语言问数项目
⚡项目四:基于XXL-Job的高并发定时秒杀商城系统
🛢️ 项目五:InfluxDB数据库服务化能力建设
技术亮点与难点
一个挑战。
处理线上问题,处理偶现问题
先止血,后排查。。?
一次排查问题。
cpu飙升,发现是一个接口有io操作,并发大了就卡住了。。
首先,停掉回写接口,把cpu降下来,恢复服务
分析,不是计算型的,所以多线程没用,要考虑优化io查询,cmdb加索引。。
其次,如何降低并发,加缓存?异步??
doubao文档 https://www.doubao.com/docx/LBf3d5HhDo1GbBxiSpucIhmDnbb
介绍下基于 Oplog 实现的数据订阅方案,存在什么缺陷?如何处理?
1.实现原理:MongoDB 复制集生成 Oplog,完整记录库内所有 CRUD 变更;服务持续拉取解析日志,将资产变更事件推送下游系统;
2.方案优势:无业务代码埋点、低侵入;相比定时轮询,极大降低数据库查询压力;
3.现存痛点:Oplog 存在磁盘容量上限,日志滚动覆盖会造成变更丢失;消费进程宕机,窗口期变更无法捕获;
4.落地解决方案:持久化保存消费位点,增加消费中断告警;额外提供全量同步接口,支持下游进行数据补偿。
延伸引导:如果是 MySQL 环境,一般依靠 Binlog 实现同等能力,我近期也对比研究过 Binlog 与 Oplog 的设计思路异同。
详细描述防火墙自动采集整条链路,线上遇到过哪些典型问题?
链路流程:XXL-Job 下发采集任务 → 消息投递 Kafka → 采集执行服务消费任务 → 通过 API/Ansible/FTP 拉取设备配置 → 结果推送 Kafka → 采集代理消费数据,清洗入库 MongoDB。
典型故障:外部设备接口响应缓慢阻塞消费、生产速率大于消费速率引发 Kafka 消息堆积;
优化手段:消费端开启批量处理、限制单节点任务并发、异常消息转入死信队列,避免任务持续重试堵塞链路。
mongostash 同步 MongoDB 数据到 ES,出现两边数据不一致,如何排查修复?
平台查询接口响应很慢,你的标准化排查 SOP 是什么?
线上 Java 服务频繁 FullGC、出现 OOM,你的完整排查流程?
Kafka 消息堆积一般怎么分析、如何解决?
私有化交付遇到 ZooKeeper 集群无法启动,完整说下排查过程和解决方案
现象:容器环境重启后 ZooKeeper 集群启动失败,节点无法互相通信;
根因:集群配置文件硬编码节点物理 IP,容器重建之后 IP 发生变动;
解决方案:选择集群健康运行窗口期执行 reconf 动态更新集群配置,用内部域名替换固定 IP;
亮点:方案无需停机重建集群,不存在业务中断;
拓展思考:云原生容器环境部署中间件,应当尽量规避写死 IP,优先使用域名、服务发现机制。
如果让你重新设计整套 CMDB 底座,你会做哪些优化?
CMDB 大量选用 MongoDB,为什么初期没有选择 MySQL?你如何对比两种数据库?
选型原因:平台资产类型繁杂,不同设备属性差异大,需要频繁新增扩展字段;MySQL 频繁执行 DDL 修改表成本很高,MongoDB 文档模型可以灵活扩展字段,适配业务场景。
客观短板:MongoDB 不适合强事务、多表复杂关联的交易场景。
主动过渡话术:如果是订单类核心业务系统,MySQL 会更加合适,我近期系统学习 InnoDB MVCC、锁机制、索引优化等内容,能够胜任关系型数据库相关的开发与调优工作。
^^
基本概念
Maven是Apache基金会的开源项目管理和构建自动化工具,使用POM(Project Object Model) 文件描述项目结构、依赖关系和构建配置。
是否专门用于Java?
主要定位:主要用于Java项目
可扩展性:通过插件可支持其他语言(Scala、Groovy、Kotlin等)
生态系统:虽然不限于Java,但在Java生态中最为成熟
核心功能
1 | ├── 依赖管理(Dependency Management) |
Maven依赖的本质
| 内容 | 说明 | 是否必须 |
|---|---|---|
| .class文件 | 已编译的字节码(人类可读的.java源代码文件编译而来) | ✅ 必须,用于运行 |
| pom.xml | 依赖的元数据 | ✅ 必须,用于传递依赖解析 |
| 源代码(.java) | 可选,用于调试 | ❌ 可选,IDE可单独下载 |
| javadoc | API文档 | ❌ 可选,IDE可单独下载 |
1 | // pom.xml中的依赖声明 |
1 | ~/.m2/repository/com/google/guava/guava/31.1-jre/ |
| 命令 | 功能 | 说明 |
|---|---|---|
| mvn clean | 清理项目 | 删除target目录 |
| mvn compile | 编译源码 | 生成target/classes |
| mvn test | 运行测试 | 执行src/test下的测试 |
| mvn package | 打包项目 | 生成jar/war包 |
| mvn install | 安装到本地仓库 | mvn package + 将jar安装到本地 ~/.m2/repository |
| mvn deploy | 部署到远程仓库 | 发布到Nexus/Artifactory |
| mvn clean install | 清理并安装 | 常用组合命令 |
| mvn dependency:tree | 查看依赖树 | 分析依赖关系 |
| mvn spring-boot:run | 运行Spring Boot | 需要对应插件 |
A[clean] –> B[validate] –> C[compile] –> D[test] –> E[package] –> F[verify] –> G[install] –> H[deploy]
mvn compile - 编译阶段相当于:执行 javac 编译源代码
1 | # 实际操作 |
当您运行 mvn compile时,Maven 会:
解析依赖:读取 pom.xml 中的
下载依赖:从远程仓库下载到本地 ~/.m2/repository/
构建依赖图:处理传递依赖
关键点:Maven 管理的这些依赖是已经编译好的 .class 文件(JAR 包),不是 .java 文件。
然后 Maven 会:
编译您的代码:src/main/java/下的 .java 文件
使用依赖:编译时将下载的依赖 JAR 加入 classpath
打包:将您的 .class 文件 + 资源文件打包
todo:那么打包的时候到底保护包含依赖?我自己的源代码编译 .class + 依赖包的 .class ??
mvn package - 打包阶段相当于:根据packaging类型不同,将编译结果打包成可分发的格式(注意:普通mvn package生成的jar不包含依赖!依赖需要单独配置)
1 | <!-- pom.xml中指定打包类型 --> |
打包过程:
1 | # 对于jar包: |
mvn install - 安装阶段mvn install 做了两件事:
1 执行之前所有阶段:validate → compile → test → package → verify → install
2 将当前项目的构建结果安装到本地仓库,安装位置 →
1 | ~/.m2/repository/com/yourcompany/yourapp/1.0.0/ |
1 | # 标准开发流程 |
| 方式 | 插件 | 特点 | 适用场景 |
|---|---|---|---|
| 普通JAR | maven-jar-plugin | 不包含依赖 | 库项目 |
| Fat JAR | maven-assembly-plugin | 包含所有依赖 | 简单应用 |
| 可执行JAR | spring-boot-maven-plugin | Spring Boot专用 | Spring Boot应用 |
| Shadow JAR | maven-shade-plugin | 重命名包解决冲突 | 复杂依赖 |
Spring Boot项目(最常用)
1 | <!-- pom.xml --> |
1 | # 打包命令 |
项目结构
1 | my-project/ |
执行流程
1 | # 1. 清理 + 编译 |
1 | File → Settings → Build, Execution, Deployment → Build Tools → Maven |
症状:点击刷新后,依赖仍然报红
解决方案:
强制刷新:
1 | # 命令行执行 |
-U 参数强制更新快照版本
删除本地仓库:
1 | # Windows |
清除IDEA缓存:
1 | File → Invalidate Caches and Restart |
解决方案:
配置阿里云镜像(settings.xml):
1 | <mirrors> |
IDEA配置镜像:
1 | File → Settings → Build Tools → Maven |
症状:NoSuchMethodError, ClassNotFoundException
排查命令:
1 | # 查看依赖树 |
IDEA可视化排查:
解决冲突示例:
1 | <dependency> |
1 | <!-- 统一管理版本 --> |
| 图标 | 功能 | 快捷键 |
|---|---|---|
| 🔄 | 重新导入所有Maven项目 | Ctrl+Shift+O |
| 🏃 | 运行Maven目标 | 右键→Run Maven |
| 📊 | 显示依赖图 | 右键→Show Dependencies |
| 🧹 | 执行clean | 双击Lifecycle→clean |
1 | <!-- pom.xml 中定义不同环境 --> |
在IDEA Maven工具窗口的Profiles中勾选激活。
当遇到顽固依赖问题时,按顺序执行:
第一步:清理缓存
1 | mvn clean install -U |
第二步:删除本地仓库对应目录
1 | # 删除有问题依赖的目录 |
第三步:IDEA完全清理
.idea 目录和 *.iml 文件第四步:检查Maven配置
1 | # 查看有效POM |
第五步:网络代理检查
1 | <!-- settings.xml 配置代理 --> |
使用依赖锁定
1 | <plugin> |
定期清理本地仓库
1 | # 清理失败下载 |
使用CI/CD环境验证
在Jenkins/GitHub Actions中设置定期构建,提前发现问题。
| 错误代码 | 含义 | 解决方案 |
|---|---|---|
| 501 HTTPS Required | 仓库需要HTTPS | 更新settings.xml,使用https仓库 |
| 401 Unauthorized | 认证失败 | 配置正确的server认证 |
| Could not transfer artifact | 网络/权限 | 检查网络,清理.lastUpdated文件 |
| No compiler is provided | JDK配置错误 | 配置JAVA_HOME,或在pom中指定javac |
离线模式(网络不稳定时)
1 | mvn clean install -o |
跳过测试
1 | mvn clean install -DskipTests |
多线程构建
1 | mvn clean install -T 4 |
调试模式
1 | mvn -X clean install |
📚 文档链接: 快速入门 | Milvus 文档
向量嵌入是从机器学习模型中提取的数值表示,捕捉非结构化数据的语义含义。这些嵌入通过神经网络或变压器架构对数据中的复杂相关性进行分析,创建一个密集的向量空间,其中每个点对应于数据对象(如文档中的词)的“含义”。
这个过程将文本或其他非结构化数据转换为反映语义相似性的向量——在这个多维空间中,意义相关的词被放置得更近,从而实现一种称为“密集向量搜索”的搜索方式。这与依赖精确匹配和使用稀疏向量的传统关键词搜索形成对比。向量嵌入的发展,通常源于大型科技公司广泛训练的基础模型,使得搜索能够捕捉数据的本质,超越词汇或稀疏向量搜索方法的局限性。
向量:可以理解为在多维空间中的一个点,它由一组数字(坐标)表示。在 AI 中,无论是文本、图像还是声音,都可以通过特定模型(如 qwen3-embedding-4b-torch)转换为一个向量。这个向量捕捉了原始数据的深层特征。
维度:就是指这个向量有多少个数字。例如,一个 [0.12, 0.45, -0.23, …, 0.78]的向量,如果它有 1024 个数字,我们就说它是一个 1024 维 的向量。维度的选择通常由您选用的嵌入模型决定,并且在创建 Milvus 集合时必须正确定义,因为所有存入的向量都必须有相同的维度。
非结构化数据(如文本、图像和音频)格式各异,蕴含丰富的潜在语义,因此分析起来极具挑战性。Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON,为您节省了维护多个数据库系统的精力。
与处理结构化数据并执行精确搜索操作的传统关系数据库不同,向量数据库擅长使用 Approximate Nearest Neighbor(ANN)算法等技术进行语义相似性搜索。这种能力对于开发推荐系统、聊天机器人和多媒体内容搜索工具等各种领域的应用程序,以及解决 ChatGPT 等大型语言模型和 AI 带来的挑战(如理解上下文和细微差别以及 AI 幻觉)至关重要。
| Milvus 概念 | 类比关系型数据库概念 | 说明 |
|---|---|---|
| Collection(集合) | Table(表) | 存储向量和关联元数据(如文本内容、来源)的基本单位。 |
| Entity(实体) | Row(行) | 一条完整的记录,包含主键、向量字段和标量字段(元数据)。 |
| Field(字段) | Column(列) | 包括向量字段(存储向量)和标量字段(存储 ID、标签等结构化数据)。 |
| Index(索引) | Index(索引) | 为向量字段建立的索引(如 HNSW、IVF_FLAT),是高速检索的关键。 |
写入数据(以 Python 为例):
1 | from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType |
读取与搜索:
1 | # 用户提出问题,并转换为向量 |
Milvus 支持的搜索类型
ANN 搜索:查找最接近查询向量的前 K 个向量。
过滤搜索:在指定的过滤条件下执行 ANN 搜索。
范围搜索:查找查询向量指定半径范围内的向量。
混合搜索:基于多个向量场进行 ANN 搜索。
全文搜索:基于 BM25 的全文搜索。
获取:根据主键检索数据。
查询使用特定表达式检索数据。
Rerankers
在基础的 RAG 流程中,系统通过 Embedding 模型 将用户查询和知识库文档转换为向量,然后利用向量数据库进行快速的相似性搜索,找出最相关的几个文档片段作为上下文提供给 LLM 。然而,这种基于向量相似度的检索有时无法完美捕捉深层次的语义关联,可能返回一些看似相关实则无关的“噪声”文档 。
Reranker 模型的作用就在于此。它通常在向量检索之后介入,像一个专业的裁判,对初步检索到的候选文档(例如 Top 20 或 Top 50)进行二次精排 。其核心工作原理是:
1、精细化语义理解:不同于 Embedding 模型分别处理查询和文档,典型的 Cross-encoder Reranker 会将查询和一个候选文档同时输入模型,让模型直接分析两者之间的交互信息,从而给出一个更精确的相关性分数 。
2、结果重排序:Reranker 为所有候选文档重新打分并排序,最终只将排名最靠前的、真正相关的少量文档(如 Top 3 或 Top 5)传递给 LLM 。
在 RAG 流程中,Milvus 扮演着 知识库与高速检索引擎 的角色。
qwen3-235b-a22b),由它来生成精准、有据可依的最终答案。人工智能集成:
Agentic RAG(智能体驱动的 RAG,Agentic RAG = RAG + Agent):基础的 RAG 中,检索-增强-生成是一次性完成的。而Agentic RAG则引入了“智能体”的概念,智能体可以根据对大模型初步生成内容的理解,主动地、多次地 与向量数据库(Milvus)进行交互。这使 RAG 系统从静态的“文档查找”升级为动态的、具有决策能力的“研究助手”。例如:
AI Agent的本质是能够感知环境、自主决策并执行行动的智能实体。与传统AI系统最大的区别在于Agent具有自主性、反应性、目标导向和学习能力,它不再是简单的工具,而是能够主动规划和完成复杂任务的智能体。从1997年击败国际象棋世界冠军的IBM“深蓝”,到2011年苹果推出的个人助理Siri,都展示了Agent在特定领域的强大能力,关键的转折点发生在2023年左右,大语言模型LLM的出现为Agent提供了强大的通用理解和推理能力,使其不再局限于单一任务。
Function Calling:函数调用,是LLM的一种能力,允许模型根据用户输入决定何时以及如何调用哪个函数(Tool),并以结构化格式(如JSON)输出函数调用参数。然后由外部系统执行该函数。RAG(检索增强生成):通过从外部知识库检索相关信息,并将其作为上下文提供给LLM,从而生成更准确、更相关的回答。MCP(模型上下文协议):MCP可以包含本地tools和外部API,但通常 MCP更强调于将工具(无论是本地tools还是外部API)以标准化的上下文协议暴露给AI模型。MCP可以看作是一个中间层,它将工具抽象成标准的接口,使得AI Agent可以通过统一的协议来调用这些工具,从而实现模型与工具之间的解耦。
1 | #### main.py |
1 | #### tools.py |
MCP 可以看作是一个中间层,它将工具抽象成标准的接口,使得AI Agent可以通过统一的协议来调用这些工具,从而实现模型与工具之间的解耦。MCP 可以包含本地tools和外部API,但通常 MCP更强调于将工具(无论是本地tools还是外部API)以标准化的上下文协议暴露给AI模型。
RAG 的核心思想是:在让大模型回答问题之前,先从一个外部的、可随时更新的知识库中检索相关信息,然后将这些“新鲜”信息作为上下文和问题一起交给模型,从而引导模型生成更准确、及时且可追溯的答案。它能有效减少模型“幻觉”(即胡编乱造),让AI应用在知识密集型任务中变得真正可靠。以及,它能帮助构建专业领域专家对话机器人。
一个典型的RAG系统工作流程包含三个关键阶段:

业务逻辑
LangChain 是一个功能强大的大语言模型应用开发框架。与Spring在Java后端开发中的定位类似。
https://python.langchain.com/docs/concepts/
https://arxiv.org/abs/2302.07842
LangChain 包:通过 pip 命令(类似于Java的Maven或Gradle)安装到项目中,避免重复造轮子。
LangGraph 核心认知:用“有向图”构建智能体的新一代框架,是 用于构建有状态、多步骤、多分支智能体(Agent) 的框架,核心是将 Agent 的行为拆解为节点(Nodes) 和边(Edges),用有向图(Directed Graph) 替代老版本的“线性循环” 以支持更复杂的流程编排。
LangGraph 可以理解为:给 Agent 设计“流程图”的工具,而老版本 ReAct Agent 只是这个流程图中最基础的“单循环分支”。
https://docs.langchain.com/oss/python/langgraph/overview
1 | { |
InMemorySaver),支持中断、恢复、回溯(比如多轮对话的上下文保留)。cmdb_search、cmdb_query)。用户输入清洗节点 → LLM 思考节点 → CMDB 工具节点 → 日志工具节点 → 回答格式化节点cmdb_search 节点;如果输出“需要调用日志工具”,则跳转到 log_search 节点;如果输出“无需调用工具”,则跳转到“回答节点”。InMemorySaver 就是内存级的检查点,还可以用 Redis、SQL 实现持久化)。1 | [入口节点:用户输入] |
cmdb_search),LangGraph 只通过工具调用节点统一管理,支持多工具的动态选择和调用。cmdb_search,再调用 cmdb_query 统计)。AgentExecutor)是 LangGraph 的简化版,两者的核心差异在于流程的编排能力:| 维度 | 老版本 ReAct Agent(AgentExecutor) | LangGraph |
|---|---|---|
| 架构基础 | 线性循环(Single Loop) | 有向图(Directed Graph) |
| 节点/边 | 无物理节点拆分,只有“思考→工具”的逻辑两步;无多分支边,只有单一循环。 | 支持多节点、多类型边(条件边、普通边),可编排复杂流程。 |
| 状态管理 | 临时状态(每次循环重新生成,无持久化) | 统一的状态对象,支持持久化、回溯(Checkpoint)。 |
| 流程灵活性 | 只能“思考→工具→思考”的单一循环,多工具需按顺序调用(一次一个)。 | 支持多分支(比如不同工具的并行调用)、条件跳转、中断恢复。 |
| 扩展性 | 扩展复杂流程(如多工具并行)需要大量自定义代码。 | 通过图的编排即可实现,无需修改核心逻辑。 |
老版本 ReAct Agent 的核心是 AgentExecutor 的单一循环: |
1 | while True: |
cmdb_search,再调用 alert_search,通过多次循环实现。集成到Java
MongoDB 是一个基于文档的开源 NoSQL 数据库,使用类似 JSON 的文档模型灵活存储数据,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
https://www.mongodb.com/zh-cn/docs/manual/crud/
| MongoDB 概念 | 类比 MySQL 概念 | 类比 Elasticsearch 概念 | 核心解析 |
|---|---|---|---|
| 文档 (Document) | 行 (Row) | 文档 (Document) | 数据的基本单元,是一个键值对的有序集合。它类似于一条完整的记录。 |
| 集合 (Collection) | 表 (Table) | 索引 (Index) | 一组文档的容器。它类似于一张数据表。 |
| 数据库 (Database) | 数据库 (Database) | 无直接对应(可类比为索引的逻辑分组) | 最高层的命名空间,用于组织和管理多个集合。一个 MongoDB 实例可以运行多个数据库,每个数据库在文件系统上有独立的文件。 |
| 字段 (Field) | 列 (Column) | 字段 (Field) | 文档中的键值对,代表一个数据属性。 |
ALTER TABLE 操作。| 特性 | MongoDB | MySQL | Elasticsearch |
|---|---|---|---|
| 数据模型 | 文档模型,动态模式 | 关系模型,固定模式 | 文档模型,可定义映射 |
| 查询语言 | 面向对象的 API 方法 | 标准 SQL 语句 | JSON-based DSL |
| 核心优势 | 敏捷开发、水平扩展、存储复杂数据结构 | 复杂查询、事务一致性、数据完整性 | 全文搜索、日志分析、复杂聚合 |
| 典型场景 | 内容管理系统、用户画像、实时分析、物联网 | 金融交易系统、ERP、CRM等需要严格事务的系统 | 搜索引擎、日志和指标分析、应用内搜索 |
| 操作类型 | 方法示例 | 功能说明 |
|---|---|---|
| 创建 (Create) | db.hosts.insertOne({hostname: "web-01", ip: "192.168.1.100"}) |
向集合中插入一条新文档。若集合不存在,会自动创建。 |
| 批量创建 | db.hosts.insertMany([{hostname: "web-01"}, {hostname: "db-01"}]) |
批量插入多条文档。 |
| 查询 (Read) | db.hosts.find({status: "running"}) |
查询所有符合条件的文档。不传参数则返回所有文档。 |
| 条件查询 | db.hosts.find({"specs.memory": {$gte: 8}}, {hostname: 1, _id: 0}) |
使用查询操作符进行过滤,并使用投影选择返回的字段。 |
| 更新 (Update) | db.hosts.updateOne({hostname: "web-01"}, {$set: {"specs.memory": 32}}) |
更新一条匹配的文档。$set 操作符用于修改特定字段的值。 |
| 批量更新 | db.hosts.updateMany({environment: "production"}, {$inc: {visits: 1}}) |
更新所有匹配的文档。$inc 操作符用于将字段的值增加指定数额。 |
| 删除 (Delete) | db.hosts.deleteOne({hostname: "web-01"}) |
删除一条匹配的文档。 |
| 批量删除 | db.hosts.deleteMany({status: "terminated"}) |
删除所有匹配的文档。 |
insertMany 这样的多文档操作,默认情况下并非一个整体事务。$gt (大于), $gte (大于等于), $lt (小于), $lte (小于等于), $ne (不等于)。$and, $or, $in (匹配数组中任意值), $nin (不匹配数组中任何值)。1 | // 创建 |
1 | // 查询与投影 |
1 | // 更新操作符 |
1 | // 逻辑组合查询 |
1 | // 数组查询 |
1 | // 正则表达式与文本搜索 |
1 | // 场景:找出所有生产环境的Linux主机 |
1 | // 场景:找出内存大于8G的生产环境主机,按内存降序排列,只显示主机名和内存 |
1 | // 目标:查询生产环境的应用,并获取其运行主机的详细信息 |
1 | // 应用文档示例 |
1 | db.hosts.aggregate([ |
1 | db.applications.aggregate([ |
db.hosts.createIndex({ hostname: 1 })db.hosts.createIndex({ environment: 1, status: 1 }) db.hosts.createIndex({ tags: 1 })db.hosts.createIndex({ description: "text" })db.logs.createIndex({ createdAt: 1 }, { expireAfterSeconds: 3600 })1 | Primary(主节点)← 读写操作 |
1 | // 复制集配置 |
1 | // 强一致性写操作 |
1 | // 好的分片键:基数高、分布均匀 |
1 | 自然语言查询 → MCP Server → 查询解析器 → MongoDB查询生成器 → 结果格式化 |
1 | from mcp import MCPServer, Context |
1 | 你是一个CMDB专家,可以查询和分析基础设施信息。 |
1 | # 支持复杂查询的扩展工具 |
Docker 是一种开源平台,一种快速构建、运行和管理应用的工具。它使用容器化技术,使得应用程序及其依赖性可以打包到一个容器中,并在任何支持 Docker 的环境中运行。
1 MobarXterm 通过 SSH 连接 linux虚拟机,操作虚拟机上的 Docker。
2 Windows本地:通过wsl安装Linux发行版本,安装docker desktop(将自动在WSL中配置Docker环境,借助linux内核运行)
1 | docker run -d \ # 创建并运行一个容器,-d 是让容器在后台运行;同一个镜像可创建多个容器 |
1 | docker images # 查看本地镜像 |
镜像结构:入口,层,基础镜像。分层的好处是可复用,,
docker build 命令构建镜像。(如java项目还需要jar包)docker run 命令基于构建的镜像创建和运行容器。1 | docker volumels # 查看数据卷 |
容器编排是指在生产环境中管理和协调多个容器的过程。Docker 提供了 Docker Compose 工具,用于定义和运行多容器的应用。
Kubernetes是一个开源的容器编排引擎,可以用来管理容器化的应用,包括容器的自动化的部署、扩容、缩容、升级、回滚等等;
它是Google在2014年开源的一个项目,它的前身是Google内部的Borg系统。
在Kubernetes出现之前,我们一般都是使用Docker来管理容器化的应用,但是Docker只是一个单机的容器管理工具,它只能管理单个节点上的容器,当我们的应用程序需要运行在多个节点上的时候,就需要使用一些其他的工具来管理这些节点,比如Docker Swarm、Mesos、Kubernetes等等;
这些工具都是容器编排引擎,它们可以用来管理多个节点上的容器,但是它们之间也有一些区别,比如Docker Swarm是Docker官方提供的一个容器编排引擎,它的功能比较简单,适合于一些小型的、简单的场景,而Mesos和Kubernetes则是比较复杂的容器编排引擎;
Mesos是Apache基金会的一个开源项目,而Kubernetes是Google在2014年开源的,目前已经成为了CNCF(Cloud Native Computing Foundation)的一个顶级项目,基本上已经成为了容器编排引擎的事实标准了。

Node:k8s集群节点,可以是物理机/虚拟机
Pod:k8s最小调度单元,容器(运行app/数据库/..镜像)的抽象,可以是一/多个容器的组合,但除非高度耦合,一个pod只运行一个容器
Service:将一组pod封装成一个服务并且提供统一访问入口(解决了一组数据库pod中一个重建后ip变化的问题,类似于“服务发现”)
Ingress:为了对外提供服务,将外部请求路由转发到内部集群的service上
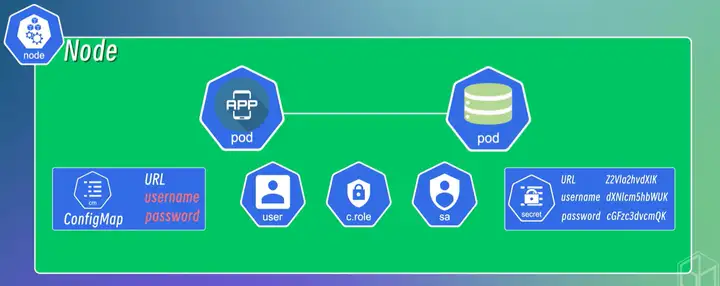
ConfigMap:封装配置信息
Secret:封装敏感信息
其他安全机制:网络安全,访问控制,身份认证
Volumn:将数据挂在到本地磁盘或远程存储上,实现持久化存储
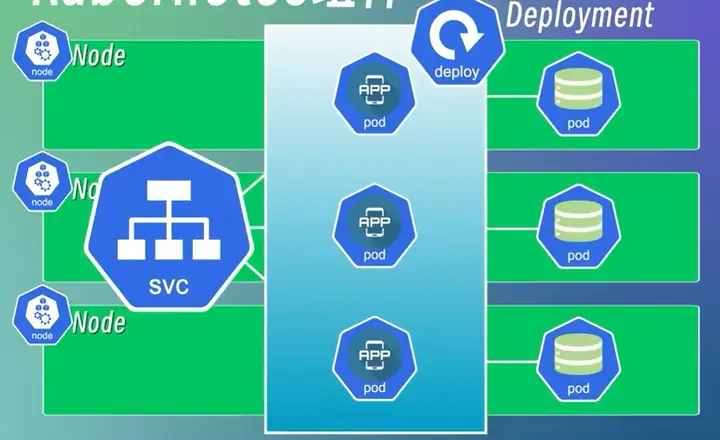
Deployment:部署无状态应用程序,将一/多个Pod组合到一起;冗余备份,相当于对Pod的抽象;具有副本控制、滚动更新、自动扩缩容等功能,实现应用程序的高可用
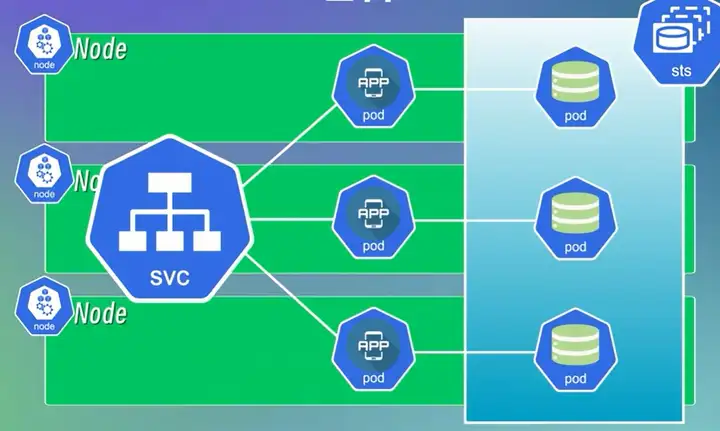
Statefulset:部署有状态应用程序,如DB、MQ、缓存以及保留会话状态的应用程序
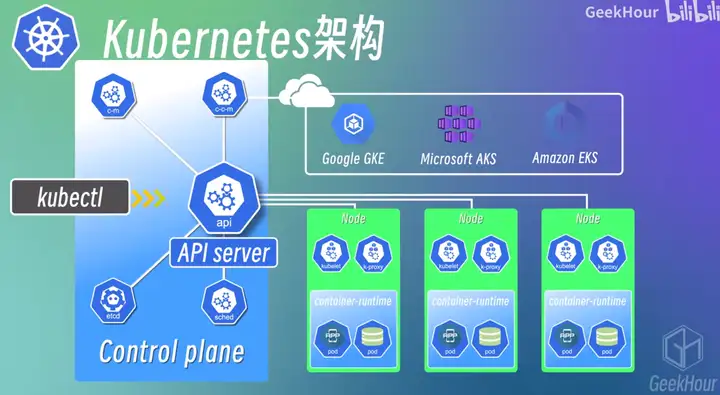
分为Master和Worker节点
apiserver:位于master节点上,是k8s集群的API接口;交互方式包括 kubectl 命令行、Dashboard界面或API接口
pv
pvc
lvm
service
ingress
集群间dns
外部访问
1 | # 查看帮助 |
1 | # 创建并运行一个指定的镜像 |
1 | # 查看集群中某一类型的资源 |
1 | # 更新某个资源的标签 |
1 | # 进入某个Pod的容器中 |
Portainer 是一个轻量级的容器管理工具,可以用来管理Docker和Kubernetes,它提供了一个Web界面来方便我们管理容器
官方网址: https://www.portainer.io/
Helm 是一个Kubernetes的包管理工具,可以用来管理Kubernetes的应用,它提供了一个命令行工具来方便我们管理Kubernetes的应用
官方网址: https://helm.sh/
https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/
InfluxDB 是一个由InfluxData开发的开源时序型数据库,专注于海量时序数据的高性能读、高性能写、高效存储与实时分析等;
在DB-Engines Ranking时序型数据库排行榜上排名第一,广泛应用于DevOps监控、IoT监控、实时分析等场景。
https://jasper-zhang1.gitbooks.io/influxdb/content/Introduction/getting_start.html
influxdb-cluster 是InfluxDB的集群版本,InfluxDB Enterprise 的开源替代方案,设计用于大规模数据存储和高可用性需求。
可以实现数据的分片和复制,从而提高系统的可用性和扩展性。数据安全。operator缺失
https://github.com/chengshiwen/influxdb-cluster/wiki
InfluxDB Enterprise由两组软件进程组成: Data 数据节点 和 Meta 元节点。集群内的通信是这样的:

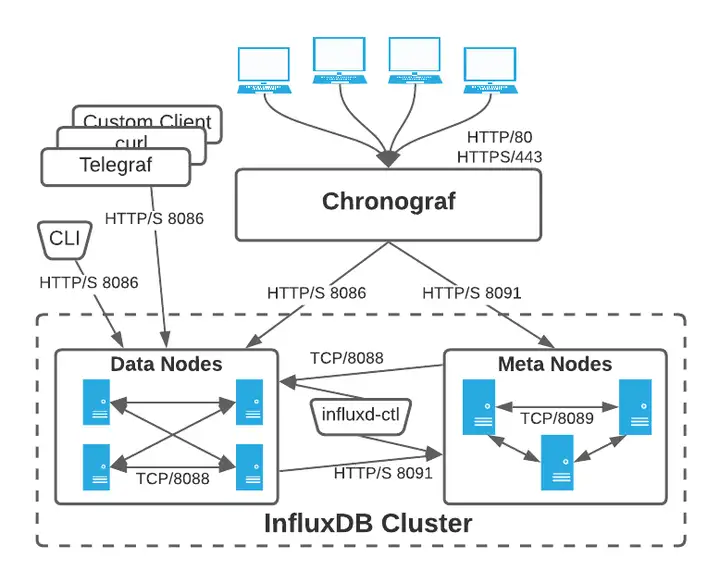
influxdb使用的默认端口号为分别为用于meta集群内部服务的8091端口,meta节点通信的8089端口,data集群内部服务的8088端口,以及data节点对外提供http服务的8086端
InfluxDB 集群中,一个节点要么是专门用于存储和查询时间序列数据的数据节点,要么是专门用于存储集群元数据的元节点。数据节点负责存储实际的数据和处理查询请求,而元节点则负责管理集群的元数据,包括节点信息、数据库和保留策略等。
元节点保存以下所有元数据:
元节点将这些数据保存在磁盘上的Raft数据库中,由BoltDB提供支持。默认情况下,Raft数据库是/var/lib/influxdb/meta/raft.db。
注意:Meta节点需要/ Meta目录。
influxd-meta 元数据服务1 | # 配置文件示例(meta节点) |
influxd-ctl 集群管理1 | # 查看分片分布 |
数据节点保存所有原始时间序列数据和元数据,包括:
在磁盘上,数据总是按照
influx CLI工具1 | # 进入容器执行CLI |
influxd 数据节点服务1 | # 查看运行状态 |
influx_inspect 数据工具1 | # 导出TSM文件(需进入容器) |
通信协议
| 组件 | 端口 | 用途 | 协议 |
|---|---|---|---|
| Meta节点间 | 8089 | Raft协议同步元数据 | TCP |
| Data节点间 | 8088 | 分片数据复制 | TCP |
| Data→Meta节点 | 8091 | 注册节点/获取分片元信息 | HTTP |
核心交互场景
节点注册 : Data节点启动时通过HTTP API向Meta节点注册(POST /data)
分片分配 : Meta节点根据replication-factor策略分配分片到Data节点
写入协调 : 客户端写入数据时,由Meta节点确定目标分片所在Data节点
故障转移 : Meta节点检测Data节点离线后,自动通过Hinted Handoff机制转移副本
一个集群至少要有三个独立的元节点才能允许一个节点的丢失,如果要容忍n个节点的丢失则需要2n+1个元节点。集群的元节点的数目应该为奇数。不要是偶数元节点,因为这样在特定的配置下会导致故障。
一个集群运行只有一个数据节点,但这样数据就没有冗余了。这里的冗余通过写数据的RP中的副本个数来设置。一个集群在丢失n-1个数据节点后仍然能返回完整的数据,其中n是副本个数。为了在集群内实现最佳数据分配,我们建议数据节点的个数为偶数。
1 | $ influx -precision rfc3339 |
1 | <measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp] |
1 | > use testdb |
1 | > SELECT "host", "region", "value" FROM "cpu" |
1 | curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000' |
1 | curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT \"value\" FROM \"cpu_load_short\" WHERE \"region\"='us-west'" |
shard := shardGroup.shards[fnv.New64a(key) % len(shardGroup.Shards)]
4/2=2 个分片(Shard 1 & 2)cpu,host=svr1 usage=80:Series Key = cpu,host=svr1,哈希值模2=1 ⇒ 分片2,数据同时写入节点 C 和 DSELECT * FROM cpu WHERE time > '2025-04-02':定位到 2025-04-02 分片组, 协调节点同时向 A/B(分片1)和 C/D(分片2)发起查询, 合并结果后返回Docker安装操作单例InfluxDB https://www.cnblogs.com/nhdlb/p/16409849.html
Docker快速开始集群InfluxDB https://github.com/chengshiwen/influxdb-cluster/wiki#docker-%E5%BF%AB%E9%80%9F%E5%BC%80%E5%A7%8B
在使用容器多节点部署InfluxDB时,数据库、容器、Docker、主机和Kubernetes(k8s)之间的关系可以理解如下:
Kubernetes 存储与 InfluxDB Shard 的关系解析
/var/lib/influxdb/data 目录下。/var/lib/influxdb/data/<database>/<retention_policy>/<shard_id>。Delete(默认),删除 PVC 会导致 Kubernetes 清理其绑定的 PV 及底层存储数据(如 NFS 目录、云盘等)。此时 /var/lib/influxdb 下的 data、meta 目录被清空,导致 Shard 文件丢失。ERR: shard not found 错误。https://docs.influxdata.com/enterprise_influxdb/v1/administration/backup-and-restore/
https://blog.csdn.net/weixin_46560589/article/details/127748939
InfluxDB Enterprise支持在集群实例、单个数据库和保留策略以及单个分片中备份和恢复数据。
1 | influxd backup -portable /path/to/backup |
1 | influxd backup -portable -database <database_name> /path/to/backup |
1 | influxd backup -portable -start <timestamp> /path/to/backup |
备份的数据可以恢复到新实例或现有实例中。
1 | influxd restore -portable /path/to/backup |
1 | influxd restore -portable -db <database_name> /path/to/backup |
-newdb 选项来实现:1 | influxd restore -portable -db <old_database_name> -newdb <new_database_name> /path/to/backup |
对于大多数InfluxDB Enterprise应用程序,备份和恢复实用程序提供了备份和恢复策略所需的工具。但是,在某些情况下,标准备份和恢复实用程序可能无法充分处理应用程序中的大量数据。作为标准备份和恢复实用程序的替代方案,可以使用InfluxDB influx_inspect export和涌入-import命令为灾难恢复和备份策略创建备份和恢复过程。
1 | root@influxdb-e2cb6c913a191e56c134e-data-0:/# influx_inspect export -datadir "/var/lib/influxdb/data" -waldir "/var/lib/influxdb/wal" -out "influxdb_test01_dump_out" -database "test01" -start "2024-10-22T00:00:00Z" |
1 | root@influxdb-e73f149ff7192bd87d190-data-1:/# influx -import -path='influxdb_test01_dump_out' -precision=ns -username='' -password='' |
-database,加 -compress-compressed 导入压缩文件,本质上是先解压后倒入Data节点迁移方案评审:先迁移后逐个恢复分片数据。已验证在分片副本大小70M、写入数据达2000point/s的情况下直接copy-shard会导致增量数据丢失,考虑在copy-shard前先执行truncate-shards截断热分片(集群中所有写入最新数据的分片,截断后关闭写入,变成冷分片),并在所有Data节点上创建该分片的新热分片副本,也就是在迁移节点上恢复了全部原有分片的新热分片副本,最新数据写入这个副本,然后再逐个从健康节点上的冷分片副本copy-shard恢复出分片的历史数据(迁移前分片副本原有的数据&迁移过程中未能写入的数据),该分片数据完全恢复;自测符合预期
1 | kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl show-shards # 或influx命令行执行show shards |
1 | kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl remove-data influxdb-xx-data-0.influxdb-xx-data:8088 |
1 | kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl truncate-shards |
1 | # 对于_internal分片的转移 先copy后remove |
1 | # 分片的物理文件 wal&tsm |
1 | # 可能要等wal落tsm |