InfluxDB 是一个由InfluxData开发的开源时序型数据库,专注于海量时序数据的高性能读、高性能写、高效存储与实时分析等;
在DB-Engines Ranking时序型数据库排行榜上排名第一,广泛应用于DevOps监控、IoT监控、实时分析等场景。
https://jasper-zhang1.gitbooks.io/influxdb/content/Introduction/getting_start.html
influxdb-cluster 是InfluxDB的集群版本,InfluxDB Enterprise 的开源替代方案,设计用于大规模数据存储和高可用性需求。
可以实现数据的分片和复制,从而提高系统的可用性和扩展性。数据安全。operator缺失
https://github.com/chengshiwen/influxdb-cluster/wiki
集群体系结构
InfluxDB Enterprise由两组软件进程组成: Data 数据节点 和 Meta 元节点。集群内的通信是这样的:

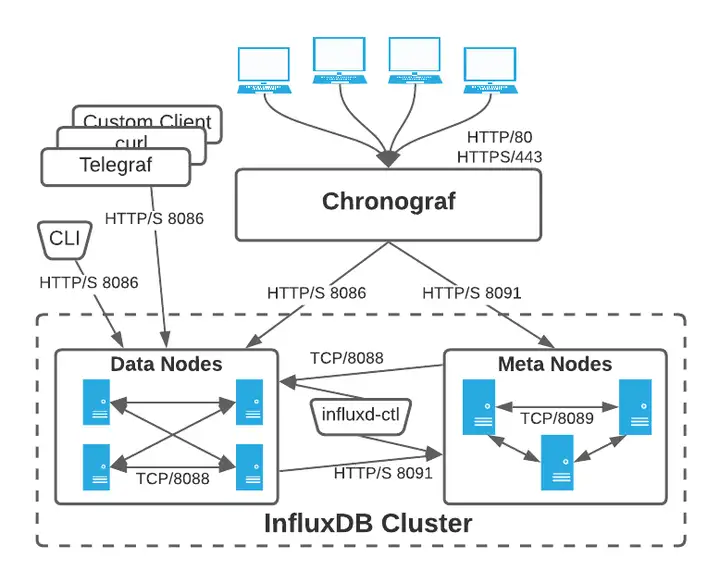
influxdb使用的默认端口号为分别为用于meta集群内部服务的8091端口,meta节点通信的8089端口,data集群内部服务的8088端口,以及data节点对外提供http服务的8086端
- Meta 节点通过 TCP 协议和 Raft 共识协议相互通信,默认都使用端口 8089,此端口必须在 Meta 节点之间是可访问的。默认 Meta 节点还将公开绑定到端口 8091 的 HTTP API,influxd-ctl 命令使用该 API。
- Data 节点通过绑定到端口 8088 的 TCP 协议相互通信。Data 节点通过绑定到 8091 的 HTTP API 与 Meta 节点通信。这些端口必须在 Meta 节点和 Data 节点之间是可访问的。
- 在集群内,所有 Meta 节点都必须与所有其它 Meta 节点通信。所有 Data 节点必须与所有其它 Data 节点和所有 Meta 节点通信。
Where data lives
InfluxDB 集群中,一个节点要么是专门用于存储和查询时间序列数据的数据节点,要么是专门用于存储集群元数据的元节点。数据节点负责存储实际的数据和处理查询请求,而元节点则负责管理集群的元数据,包括节点信息、数据库和保留策略等。
Meta
元节点保存以下所有元数据:
- 集群中的所有节点及其角色
- 集群中存在的所有数据库和保留策略
- 所有分片和分片组,以及它们存在于哪些节点上
- 集群用户及其权限
- 所有连续查询
元节点将这些数据保存在磁盘上的Raft数据库中,由BoltDB提供支持。默认情况下,Raft数据库是/var/lib/influxdb/meta/raft.db。
注意:Meta节点需要/ Meta目录。
influxd-meta元数据服务1
2
3
4
5# 配置文件示例(meta节点)
[meta]
dir = "/var/lib/influxdb/meta" # 元数据存储路径
bind-address = ":8089" # Raft协议通信端口
http-bind-address = ":8091" # 管理API端口influxd-ctl集群管理1
2
3
4
5
6
7
8# 查看分片分布
kubectl exec influxdb-meta-0 -- influxd-ctl show-shards
# 强制同步分片到新节点
kubectl exec influxdb-meta-0 -- influxd-ctl copy-shard 3 influxdb-data-0:8088
# 节点维护操作
influxd-ctl remove-data influxdb-data-0:8088 # 下线节点
# 检查Meta节点Raft状态
kubectl exec influxdb-meta-0 -- influxd-ctl raft-state
Data
数据节点保存所有原始时间序列数据和元数据,包括:
- measurements
- tag keys and values
- field keys and values
在磁盘上,数据总是按照
influxCLI工具1
2
3
4
5
6
7# 进入容器执行CLI
kubectl exec -it influxdb-data-0 -n influxdb -- influx -username admin -password 'xxx'
# 常用命令
SHOW DATABASES; # 显示所有数据库
SELECT * FROM cpu; # 查询数据
CREATE RETENTION POLICY "1d" ON db3 DURATION 1d REPLICATION 2; # 创建保留策略influxd数据节点服务1
2
3
4
5
6# 查看运行状态
kubectl exec influxdb-data-0 -- ps aux | grep influxd
# 关键参数
-data-dir /var/lib/influxdb/data # 数据存储目录
-wal-dir /var/lib/influxdb/wal # WAL日志目录influx_inspect数据工具1
2
3
4
5
6
7
8# 导出TSM文件(需进入容器)
kubectl exec -it influxdb-data-0 -- influx_inspect export \
-datadir /var/lib/influxdb/data \
-waldir /var/lib/influxdb/wal \
-out backup.gz -compress
# 验证数据完整性
influx_inspect verify -dir /var/lib/influxdb/data/db3
Data 与 Meta节点交互机制
通信协议
组件 端口 用途 协议 Meta节点间 8089 Raft协议同步元数据 TCP Data节点间 8088 分片数据复制 TCP Data→Meta节点 8091 注册节点/获取分片元信息 HTTP 核心交互场景
节点注册 : Data节点启动时通过HTTP API向Meta节点注册(POST /data)
分片分配 : Meta节点根据replication-factor策略分配分片到Data节点
写入协调 : 客户端写入数据时,由Meta节点确定目标分片所在Data节点
故障转移 : Meta节点检测Data节点离线后,自动通过Hinted Handoff机制转移副本
一个集群至少要有三个独立的元节点才能允许一个节点的丢失,如果要容忍n个节点的丢失则需要2n+1个元节点。集群的元节点的数目应该为奇数。不要是偶数元节点,因为这样在特定的配置下会导致故障。
一个集群运行只有一个数据节点,但这样数据就没有冗余了。这里的冗余通过写数据的RP中的副本个数来设置。一个集群在丢失n-1个数据节点后仍然能返回完整的数据,其中n是副本个数。为了在集群内实现最佳数据分配,我们建议数据节点的个数为偶数。
术语 / Glossary
- measurement:描述了存在关联field中的数据的意义,measurement是字符串。作为tag,fields和time列的容器。相当于MySQL的table,关系/表的意思。单个measurement可以有不同的retention policy(即 一个measurement 中的不同 tag set 可以有不同的 retention policy,构成多组 series)
- Continuous Query (CQ)是在数据库内部自动周期性跑着的一个InfluxQL的查询,CQs需要在SELECT语句中使用一个函数,并且一定包括一个GROUP BY time()语句。
- Retention Policy (RP)是InfluxDB数据结构的一部分,描述了InfluxDB保存数据的长短,数据存在集群里面的副本数,以及shard group的时间范围。RPs在每个database里面是唯一的,?连同measurement和tag set定义一个series。当创建一个database时,InfluxDB会自动创建一个叫做autogen的retention policy,其duration为永远,replication factor为1,shard group的duration设为七天。
- duration:决定InfluxDB中数据保留多长时间。在duration之前的数据会自动从database中删除掉。
- replication factor:决定在集群模式下数据的副本的个数。InfluxDB在N个数据节点上复制数据,其中N就是replication factor。
- shard group duration决定了每个shard group跨越多少时间。具体间隔由retention policy中的SHARD DURATION决定。例如,如果retention policy的SHARD DURATION设置为1w,则每个shard group将跨越一周,并包含时间戳在该周内的所有点。
- series:InfluxDB数据结构的集合,一个特定的series由measurement,tag set和retention policy组成。!field set不是series的一部分
- schema:数据在InfluxDB里面怎么组织。InfluxDB的schema的基础是database,retention policy,series,measurement,tag key,tag value以及field keys。
- shard:包含实际的编码和压缩数据,并由磁盘上的TSM文件表示。 每个shard都属于唯一的一个shard group。多个shard可能存在于单个shard group中。每个shard包含一组特定的series。给定shard group中的给定series上的所有点将存储在磁盘上的相同shard(TSM文件)中。
- shard group:是shard的逻辑组合。shard group由时间和retention policy组织。包含数据的每个retention policy至少包含一个关联的shard group。给定的shard group包含其覆盖的间隔的数据的所有shard。每个shard group跨越的间隔是shard的持续时间。
InfluxDB读写
- 命令行工具
- influx命令行连接本地InfluxDB:直接通过InfluxDB的HTTP接口(如果没有修改,默认是8086)来和InfluxDB通信。(说明:也可以直接发送裸的HTTP请求来操作数据库,例如curl)InfluxDB的HTTP接口默认起在8086上,所以influx默认也是连的本地的8086端口。-precision参数表明了任何返回的时间戳的格式和精度,如 rfc3339是让InfluxDB返回RFC339格式(YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ)的时间戳。
1
2
3
4$ influx -precision rfc3339
Connected to http://localhost:8086 version 1.2.x //
InfluxDB shell 1.2.x
> - 数据格式:将数据点写入InfluxDB,只需要遵守如下的行协议:InfluxDB里存储的数据被称为时间序列数据,其包含一个数值。时序数据有零个或多个数据点,每一个都是一个指标值。数据点包括time(一个时间戳),measurement(例如cpu_load),至少一个k-v格式的field(也即指标的数值例如 “value=0.64”或者“temperature=21.2”),零个或多个tag,其一般是对于这个指标值的元数据(例如“host=server01”, “region=EMEA”)。
1
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
可以将measurement类比于SQL里的table,其主键索引总是时间戳。tag和field是在table里的其他列,tag是被索引起来的,field没有。不同之处在于InfluxDB里,你可以有几百万的measurements,不用事先定义数据的scheme,且null值不会被存储。 - 使用CLI插入单条的时间序列数据到InfluxDB中,用INSERT后跟数据点:这样一个measurement为cpu,tag是host和region,value值为0.64的数据点被写入了InfluxDB中。
1
2
3> use testdb
Using database testdb
> INSERT cpu,host=serverA,region=us_west value=0.64 - 现在我们查出写入的这笔数据:我们在写入的时候没有包含时间戳,当没有带时间戳的时候,InfluxDB会自动添加本地的当前时间作为它的时间戳。
1
2
3
4
5
6
7> SELECT "host", "region", "value" FROM "cpu"
name: cpu
---------
time host region value
2015-10-21T19:28:07.580664347Z serverA us_west 0.64
> delete FROM "cpu" WHERE "host" = 'serverA' # 不带where将删除measurement所有数据
- influx命令行连接本地InfluxDB:直接通过InfluxDB的HTTP接口(如果没有修改,默认是8086)来和InfluxDB通信。(说明:也可以直接发送裸的HTTP请求来操作数据库,例如curl)
- HTTP 请求
- 写数据
1
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000'
- 读数据
1
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT \"value\" FROM \"cpu_load_short\" WHERE \"region\"='us-west'"
- 写数据
- 客户端库,InfluxDB 提供了多种编程语言的客户端库,如Python、Go、Java等,可以方便地在应用程序中读写数据。
- 采样和数据保留 https://jasper-zhang1.gitbooks.io/influxdb/content/Guide/downsampling_and_retention.html
集群读写
- 分片Shard:InfluxDB集群读写的基本单位分片是时间序列数据的物理存储单位,每个分片包含一段时间范围内的数据。
复制因子为X,则在每个分片的数据同步到X个节点(部署influxdb的主机)上。
分片的划分依据是时间范围和数据的存储策略(Retention Policy)。在集群环境中,分片可以分布在不同的节点上,以实现数据的分布式存储和负载均衡。这样可以提高数据的读写性能和系统的可扩展性。
确定数据属于哪个分片的过程主要涉及以下几个步骤:数据写入时,首先根据时间戳确定属于哪个Shard Group(分片组)。然后,基于Measurement和Tag的值计算哈希值。最后,根据哈希值将数据分配到具体的分片。shard := shardGroup.shards[fnv.New64a(key) % len(shardGroup.Shards)]
- 分片组Shard groups:集群在一个分片组内创建分片,以最大限度地利用数据节点的数量。
分片数计算:当集群有 N 个数据节点且副本因子为 X 时,每个分片组中会创建 floor(N/X) 个分片(向下取整)
示例:若集群有 4 个数据节点,副本因子为 2,则每个分片组包含 4/2=2 个分片(每个分片在 2 个节点上复制) - 集群写入:
假设一个HTTP写操作被发送到服务器D,数据属于分片1。写操作需要被复制到分片1的所有者:数据节点A和B。当写操作进入D时,该节点从其亚转移的本地缓存中确定需要将写操作复制到A和B,并立即尝试对两者进行写操作。
每个对HTTP API的请求都可以通过一致性查询参数指定一致性级别。 https://docs.influxdata.com/enterprise_influxdb/v1/concepts/clustering/#write-consistency - 集群查询:
根据查询的时间段和数据的复制因子进行分布的。例如,如果保留策略的复制因子为4,则接收查询的协调数据节点将随机选择存储该分片副本的4个数据节点中的任何一个来接收查询。如果我们假设系统的分片持续时间为一天,那么对于查询覆盖的每一天,协调节点都会选择一个数据节点来接收当天的查询。
协调节点尽可能在本地执行和完成查询。如果一个查询必须扫描多个shard组(在上面的例子中是多个天),协调节点将查询转发给其他节点,以查找本地没有的shard。查询与扫描自己的本地数据并行转发。查询被分发到尽可能多的节点,以查询每个分片组一次。当结果从每个数据节点返回时,协调数据节点将它们组合成返回给用户的最终结果。 - Shard Group 与 Shard 的实战示例:
- 场景描述,假设有以下配置:
Retention Policy: Duration: 30d | Replication Factor: 2 | Shard Group Duration: 1d,
集群数据节点: 4 个(A/B/C/D) - 分片组创建
时间划分:每天 00:00 自动创建新的分片组(如 2025-04-02 ~ 2025-04-03)
分片数:4/2=2个分片(Shard 1 & 2) - 分片分布
分片 1 | 副本节点 A, B | 存储内容 所有哈希值模2=0的 Series Key 数据
分片 2 | 副本节点 C, D | 存储内容 所有哈希值模2=1的 Series Key 数据 - 数据写入示例
当写入cpu,host=svr1 usage=80:Series Key =cpu,host=svr1,哈希值模2=1 ⇒ 分片2,数据同时写入节点 C 和 D - 数据查询流程
查询SELECT * FROM cpu WHERE time > '2025-04-02':定位到 2025-04-02 分片组, 协调节点同时向 A/B(分片1)和 C/D(分片2)发起查询, 合并结果后返回
- 场景描述,假设有以下配置:
集群部署
Docker安装操作单例InfluxDB https://www.cnblogs.com/nhdlb/p/16409849.html
Docker快速开始集群InfluxDB https://github.com/chengshiwen/influxdb-cluster/wiki#docker-%E5%BF%AB%E9%80%9F%E5%BC%80%E5%A7%8B
在使用容器多节点部署InfluxDB时,数据库、容器、Docker、主机和Kubernetes(k8s)之间的关系可以理解如下:
- 数据库(InfluxDB):InfluxDB是一个时序数据库,用于存储和查询时间序列数据。在多节点部署中,InfluxDB可以运行在多个容器中,以实现高可用性和负载均衡。
- 容器:容器是一个轻量级、独立的运行环境,用于打包和运行应用程序及其依赖项。InfluxDB可以被打包成一个容器镜像,并在多个容器实例中运行。
- Docker:Docker是一个容器化平台,用于创建、部署和管理容器。Docker负责启动和管理运行InfluxDB的容器。
- 主机:主机是运行Docker和容器的物理或虚拟机器。在多节点部署中,可能有多个主机,每个主机上运行一个或多个InfluxDB容器。
- Kubernetes(k8s):一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。Kubernetes可以管理多个主机上的容器,提供服务发现、负载均衡、自动扩展和自愈能力。在多节点部署中,Kubernetes可以管理InfluxDB容器的部署,确保它们在多个节点上运行,并提供高可用性和扩展性。
- 关系总结:InfluxDB 作为数据库运行在 容器 中。容器 由 Docker 创建和管理。Docker 运行在 主机 上。Kubernetes 管理多个 主机 上的 Docker 容器,提供编排和管理功能。通过这种方式,InfluxDB可以在一个分布式环境中高效运行,利用Kubernetes的编排能力实现自动化管理和扩展。
Kubernetes 存储与 InfluxDB Shard 的关系解析
- PV/PVC:是 Kubernetes 管理存储资源的抽象层。PV 描述物理存储资源(如 NFS、云盘等),PVC 是 Pod 对存储资源的请求声明。PVC 绑定到 PV 后,Pod 通过挂载 PVC 使用持久化存储。
- Shard:是 InfluxDB 存储引擎的物理存储单元,表现为磁盘上的 TSM 文件(Time-Structured Merge Tree),每个 Shard 对应一个时间范围内的时序数据块。Shard 的存储路径通常位于 PVC 挂载的
/var/lib/influxdb/data目录下。
每个 Shard 包含:时间序列索引(.tsi 文件),压缩后的时序数据块(.tsm 文件),WAL(Write-Ahead Log)日志文件(.wal) 其路径结构为:/var/lib/influxdb/data/<database>/<retention_policy>/<shard_id>。 - 重建 PVC 导致数据丢失的本质问题
• PVC 删除与 PV 回收策略:若 PVC 的回收策略为Delete(默认),删除 PVC 会导致 Kubernetes 清理其绑定的 PV 及底层存储数据(如 NFS 目录、云盘等)。此时/var/lib/influxdb下的data、meta目录被清空,导致 Shard 文件丢失。
• Shard 文件丢失会导致对应时间范围的时序数据不可查询,触发ERR: shard not found错误。
• Meta 文件丢失会破坏集群元数据一致性,导致用户权限、分片策略等配置失效。
InfluxDB 备份与恢复
https://docs.influxdata.com/enterprise_influxdb/v1/administration/backup-and-restore/
https://blog.csdn.net/weixin_46560589/article/details/127748939
InfluxDB Enterprise支持在集群实例、单个数据库和保留策略以及单个分片中备份和恢复数据。
- 备份整个实例,即所有数据库(全量备份)。命令如下:
1
influxd backup -portable /path/to/backup
- 备份单个数据库
1
influxd backup -portable -database <database_name> /path/to/backup
- 增量备份:对于较大的数据集,可以进行增量备份,只备份自上次全量或增量备份以来的数据
1
influxd backup -portable -start <timestamp> /path/to/backup
备份的数据可以恢复到新实例或现有实例中。
- 恢复整个实例,包括所有的数据库。命令如下:
1
influxd restore -portable /path/to/backup
- 恢复单个数据库
1
influxd restore -portable -db <database_name> /path/to/backup
- 有时你可能希望将备份的数据恢复到另一个数据库,可以使用
-newdb选项来实现:1
influxd restore -portable -db <old_database_name> -newdb <new_database_name> /path/to/backup
导出和导入数据
对于大多数InfluxDB Enterprise应用程序,备份和恢复实用程序提供了备份和恢复策略所需的工具。但是,在某些情况下,标准备份和恢复实用程序可能无法充分处理应用程序中的大量数据。作为标准备份和恢复实用程序的替代方案,可以使用InfluxDB influx_inspect export和涌入-import命令为灾难恢复和备份策略创建备份和恢复过程。
- 数据库导出:容器层面命令,指定 数据文件和 写前日志(WAL)文件的存储目录,将指定数据库中指定时间的数据导出到指定文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15root@influxdb-e2cb6c913a191e56c134e-data-0:/# influx_inspect export -datadir "/var/lib/influxdb/data" -waldir "/var/lib/influxdb/wal" -out "influxdb_test01_dump_out" -database "test01" -start "2024-10-22T00:00:00Z"
writing out tsm file data for test01/autogen...complete.
writing out wal file data for test01/autogen...complete.
root@influxdb-e2cb6c913a191e56c134e-data-0:/# cat influxdb_test01_dump_out
# INFLUXDB EXPORT: 2024-10-22T00:00:00Z - 2262-04-11T23:47:16Z
# DDL
CREATE DATABASE test01 WITH NAME autogen
# DML
# CONTEXT-DATABASE:test01
# CONTEXT-RETENTION-POLICY:autogen
# writing tsm data
temp,location=room1 value=24.5 1729589246099070937
temp,location=room2 value=22.5 1729589253425715740
temp,location=room3 value=22 1729649010554978701
# writing wal data - 数据库导入:容器层面执行命令,使用admin账号,指定文件、数据库、时间戳精度
1
2
3
4root@influxdb-e73f149ff7192bd87d190-data-1:/# influx -import -path='influxdb_test01_dump_out' -precision=ns -username='' -password=''
2024/10/25 03:21:47 Processed 1 commands
2024/10/25 03:21:47 Processed 2 inserts
2024/10/25 03:21:47 Failed 0 inserts - 实例导出:把influxdb集群实例中所有数据库的数据导出,不加
-database,加-compress - 实例导入:加
-compressed导入压缩文件,本质上是先解压后倒入
InfluxDB节点迁移
Data节点迁移方案评审:先迁移后逐个恢复分片数据。已验证在分片副本大小70M、写入数据达2000point/s的情况下直接copy-shard会导致增量数据丢失,考虑在copy-shard前先执行truncate-shards截断热分片(集群中所有写入最新数据的分片,截断后关闭写入,变成冷分片),并在所有Data节点上创建该分片的新热分片副本,也就是在迁移节点上恢复了全部原有分片的新热分片副本,最新数据写入这个副本,然后再逐个从健康节点上的冷分片副本copy-shard恢复出分片的历史数据(迁移前分片副本原有的数据&迁移过程中未能写入的数据),该分片数据完全恢复;自测符合预期
- 在做迁移操作前,先记录迁移节点拥有的分片副本,后续从健康节点的相同副本中恢复出来;
1
kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl show-shards # 或influx命令行执行show shards
- 迁移后更新节点/分片元信息,新data-0节点丢失db1的shard3,另外_internal的db1转移到健康节点data-1上了
1
2kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl remove-data influxdb-xx-data-0.influxdb-xx-data:8088
kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl add-data influxdb-xx-data-0.influxdb-xx-data:8088 - 持续写入数据到db1(只能写入健康节点上的db1分片副本),某一时刻执行truncate-shards,db1的shard3切断,新热分片shard4的分片副本分配到data-1以及迁移后的data-0中,此刻开始写入db1的新数据在data-0和data-1上的分片中一致(一个数据库的分片可能有多个,但只有一个正在写入,其他都是冷分片)
1
kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl truncate-shards
- 最后再恢复历史数据,也就是执行迁移前的data-0节点拥有的分片副本数据,以及迁移完成前应该写入但没有写入data-0的数据。从健康的data-1上的分片副本copy-shard而来,导出文件可见data-0和data-1上的db1数据完全一致
1
2
3# 对于_internal分片的转移 先copy后remove
kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl copy-shard influxdb-xx-data-1.influxdb-xx-data:8088 influxdb-xx-data-0.influxdb-xx-data:8088 1
kubectl exec -i influxdb-xx-meta-0 -n influxdb -- influxd-ctl remove-shard influxdb-xx-data-1.influxdb-xx-data:8088 11
2
3# 分片的物理文件 wal&tsm
kubectl exec -i influxdb-xx-data-0 -n influxdb -- ls /var/lib/influxdb/data
kubectl exec -i influxdb-xx-data-0 -n influxdb -- ls /var/lib/influxdb/wal1
2
3# 可能要等wal落tsm
kubectl exec -i influxdb-xx-data-0 -n influxdb -- influx_inspect export -datadir "/var/lib/influxdb/data" -waldir "/var/lib/influxdb/wal" -out "influxdb_dump_out" -database "db1"
kubectl exec -i influxdb-xx-data-0 -n influxdb -- md5sum influxdb_dump_out