PyTorch是一个开源的Python机器学习库,基于Torch库,底层由C++实现,应用于人工智能领域,如计算机视觉和自然语言处理。它最初由Meta Platforms的人工智能研究团队开发,现在属于Linux基金会的一部分。它是在修改后的BSD许可证下发布的自由及开放源代码软件。
许多深度学习软件都是基于 PyTorch 构建的,包括特斯拉自动驾驶、Uber的Pyro、Hugging Face的Transformers、 PyTorch Lightning。
TensorBoard
打开localhost:6006,访问TensorBoard,查看TensorFlow模型的图形、损失函数、精度等信息。
1 | from tensorboardX import SummaryWriter |
1 | # Pycharm -> Terminal |
nn.Module
基本神经网络
1 | class cf(nn.Module): |
输入层(Input Layer):接受原始图像或数据作为输入。
卷积层(Convolutional Layer):进行特征提取。通过卷积操作,利用卷积核(或过滤器)从输入图像中提取特定的特征,如边缘、纹理等。卷积核会在整个图像上滑动,产生特征图。
卷积核的输入通道数与输入数据的通道数对应,卷积核的输出通道数与卷积核的数量对应。
卷积操作在神经网络中扮演着关键的角色,它通过特征提取、参数共享、空间局部性和参数数量控制等方面,使得卷积神经网络成为图像处理和计算机视觉任务中非常有效的工具。
池化层(Pooling Layer)【最大ceil, 最小floor】:降采样和减少参数,避免过拟合。池化操作对特征图进行降采样,减少特征图的尺寸,并保留重要的特征信息。常用的池化方式为最大池化(Max Pooling)和平均池化(Average Pooling)。
非线性激活:线性变换(如全连接层)在神经网络中只能实现线性映射,而现实世界中的数据和任务通常都是非线性的。为了解决这个问题,需要在网络中引入非线性激活函数,以增加网络的表达能力和灵活性。 给网络中引入非线性特征,以训练出符合各种曲线的模型。
·ReLU(Rectified Linear Unit):f(x) = max(0, x),它在x大于0时是线性的,小于等于0时为0,能够有效地解决梯度消失问题。
·Sigmoid:f(x) = 1 / (1 + exp(-x)),它将输入映射到[0, 1]区间,用于二分类问题。
·Tanh:f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x)),它将输入映射到[-1, 1]区间,也用于解决梯度消失问题。
正则化层(Regularization Layer):正则化层用于防止过拟合。过拟合是指模型在训练数据上表现良好,但在未见过的测试数据上表现较差的现象。正则化层通过添加一些额外的约束或惩罚项来控制模型的复杂度,以避免过度拟合。
·L1正则化:将参数的绝对值加入到损失函数中,使得模型倾向于产生稀疏的权重矩阵。
·L2正则化:将参数的平方加入到损失函数中,限制权重的大小,防止权重过大造成过拟合。
·Dropout正则化:随机在训练过程中丢弃一部分神经元,减少神经元之间的共适应性,提高泛化能力。
全连接层(Fully Connected Layer):将特征矩阵集合向量化。与卷积层不同,全连接层的神经元排成一列,这些神经元与前一层神经元通过权值互连,呈全连接结构。全连接层的层数以及每层神经元数并不固定。通常层数越高,神经元数目越少。
功能:进行分类。在卷积和池化层之后,通过全连接层将得到的特征映射转换为一维向量,并通过一系列的全连接神经元进行分类操作,将输入映射到对应的类别概率。
输出层(Output Layer):经过多层特征提取后,最后一层输出层可视为分类器,预测输入样本的类别。通常使用Softmax函数将全连接层的输出转换为类别概率分布,确定输入图像最可能属于哪个类别。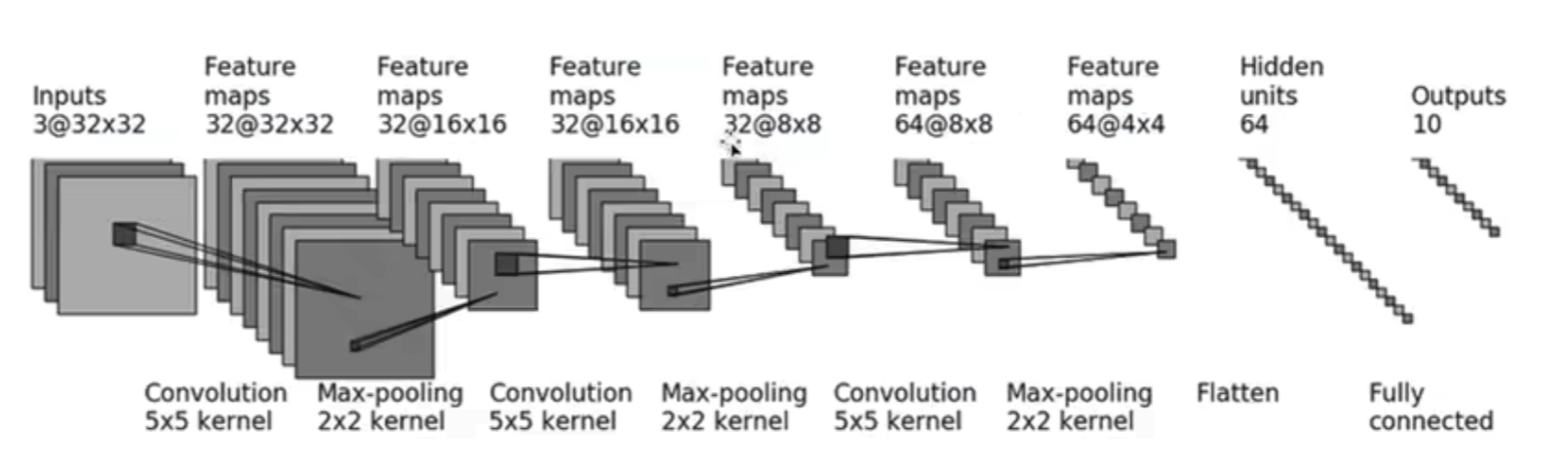
Sequential
1 | self.model1 = Sequential( |
一次训练+验证:准备数据 - 加载数据 - 准备模型 - 设置损失函数 - 设置优化器 - 开始训练 - 验证 - 聚合展示
1 | for epoch in range(20): # 共20轮训练 |
Colab
Google Colab是谷歌提供的免费Jupyter笔记本环境,不需要配置环境(本质是Linux虚拟机),可以加!运行bash命令。提供一定免费的GPU,可以跑 Tensorflow、Pytorch 等深度学习框架。Google Colab提供的资源量是受限制的,所有 Colab 运行时都会在一段时间后重置。Colab Pro 订阅者的使用量仍会受到限制,但相比非订阅者可享有的限额要多出大约一倍。Colab Pro+ 订阅者还可获享更高的稳定性。
使用Colab训练比较重要的是处理好路径的关系,找到哪个文件在哪里,文件夹的执行目录在哪里,就可以比较简单的运行起程序了,不过Colab确实存在断线问题,我们需要时刻保存好文件,因此我将权值直接保存在云盘上,这样也不会丢失。
12h的限额比较难受,有时候没到时间就限额了。因此需要及时保存训练的模型,长时间不用gpu的情况下也会被限额(Pro版也一样),因此训练完建议及时改成gpu或停止。
Google Drive
谷歌云盘,谷歌云端硬盘。免费用户可以获取15G的空间,付费用户根据套餐可以选择最大20TB的储存空间。
虚拟机根目录为 /content,谷歌云盘地址为 /content/Drive/MyDrive
深度学习库的下载
使用git clone指令进行下载,然后通过cd指令将根目录转移到了xx文件夹。此时根目录为 /content/xx
1 | !git clone https://github.com/xx/xx.git |
数据集与预训练权重的上传
数据集压缩,上传Google Drive,在colab中打开的jupyter文件(等于打开了一个Linux虚拟机本地)中挂载Google Drive;将数据集从Drive中复制到当前根目录,解压。直接将数据集布置在谷歌云盘会导致大量的云盘数据传输,且谷歌云盘和虚拟机之间存在通信带宽,速度远不及本地(虚拟机)文件,因此需要将数据集复制解压到本地(虚拟机)里进行处理。 (https://blog.csdn.net/weixin_44791964/article/details/123659637?spm=1001.2014.3001.5501)
1 | !cp /content/Drive/MyDrive/xx.zip ./ |
预训练权重存放在 /content/Drive/MyDrive/Models/xx,然后创建logs和model_data。model_data放置的是预训练文件,logs放置的是网络训练过程中产生的权值。
保存路径设置
如果将权值保存在当前根目录下的logs文件夹(/content/xx/logs),发生断线网络就白训练了,浪费大量的时间。
可以将google云盘软连接到根目录下,那么即使断线,权值也保留在云盘中。
本文之前在云盘中创建了logs文件夹(/content/Drive/MyDrive/Models/xx/logs),将该文件夹链接到当前根目录下的logs文件夹中。
1 | !ln -s /content/Drive/MyDrive/Models/xx/logs logs # 即/content/xx/logs |
开始训练
1、标注文件的处理
2、训练文件的处理
1)预训练文件的使用。
2)保存周期的设置,这个设置是因为云盘的存储空间有限,每代都保存会导致存储空间满出。
3、开始训练:!python train.py
常用 colab 命令
1 | import shutil |